Inicio
Bienvenidos y bienvenidas al sitio de Taller de Programación I - Cátedra Deymonnaz de FIUBA.
Docentes de la cátedra
-
Profesor: Ing. Pablo A. Deymonnaz
-
Jefe de Trabajos Prácticos: Ing. Martín Miletta
-
Ayudantes:
- Ing. Juan Bono
- Ing. Agustín Firmapaz
- Ing. Juan Cruz Caserío
- Noah Masri
- Camila Ayala
- Rafael Berenguel
-
Colaboradores:
- Mercedes Slepowron
- Agustina Landi
- Tomás Cichero
- Julian G. Calderon
- Juan Gulden
-
Asesor académico: Dr. Mariano Méndez
-
Asesor de la industria: Federico Carrone
Horarios de clases
Las clases serán los días lunes de 18 a 22 hs.
Desarrollo del Proyecto
En la materia vamos a trabajar con el lenguaje de programación Rust.
Desarrollaremos un Proyecto a partir de la 5ta semana de clases, en grupos de 4 (cuatro) personas.
Cada grupo tendrá el seguimiento del avance del trabajo semanalmente con un grupo docente de la cátedra.
Materias Correlativas
Las materias correlativas vigentes necesarias para poder cursar la materia dependen de la Carrera y Plan que esté cursando el estudiante:
-
Ingeniería en Informática (Plan 2023):
- Paradigmas de Programación (TB025)
- Organización del Computador (TB023)
-
Ingeniería en Informática (2021):
- Estructura del Computador (66.70)
- Algoritmos y Programación II (75.41)
-
Licenciatura en Análisis de Sistemas (1986):
- Organización del Computador (75.03)
- Algoritmos y Programación II (75.41)
-
Licenciatura en Análisis de Sistemas (2014):
- Organización del Computador (95.57)
- Algoritmos y Programación III (95.02)
-
Ingeniería en Electrónica (2009):
- Algoritmos y Programación II (95.12)
Proyectos Realizados
Listado de Proyectos Realizados
Bibliografía
La bibliografía recomendad de la materia para el aprnedizaje del lenguaje Rust es:
- The Rust Programming Language, Steve Klabnik y Carol Nichols. Es el libro oficial del lenguaje, y es la referencia principal para aprender el lenguaje.
- Programming Rust, Jim Blandy, Jason Orendorff.O'Reilly Media, Inc. Es un libro muy bueno que explica los conceptos del lenguaje de forma exhaustiva con profundidad.
- Rust in Action, Tim McNamara
Material para aprender Rust
Type System
Ownership
Otros recursos de interés
Otros recursos para consultar:
- El Lenguaje de Programación Rust. Una guía de referencia en español.
- Rust Language Cheat Sheet. Un resumen de los elementos del lenguaje, para tener a mano.
Artículos de blogs
Clases
- Clase 0 - Presentación de la materia
- Clase 1 - Introducción a Rust
- Clase 2 - Ownership, Lifetimes, Traits, Generics
- Clase 3 - Concurrencia / Procesos y Threads / Channels y Locks en Rust
- Clase 4 - Introducción a Redes / Sockets en Rust
- Clase 5 - Modelo Cliente / Servidor y Protocolo HTTP
- Clase 6 - Testing
- Clases adicionales
- Flujos de desarrollo en GIT
- GTK
- Demos - Cómo preparar demos y presentaciones del proyecto.
Guías
- Ejercicios para practicar la sintaxis del lenguaje: rustlings
- Guía 1: Introducción a Rust (pdf)
- Guía 2: Ownership (pdf)
- Guía 3: Concurrencia (pdf)
- Guía 4: Sockets (pdf)
Guía de Ejercicios 1: Introducción a Rust
Ejercicio 1 - Ahorcado
El objetivo del ejercicio es implementar un programa de consola para jugar al ahorcado.
Bienvenido al ahorcado de FIUBA!
La palabra hasta el momento es: _ _ _ _ _ _
Adivinaste las siguientes letras:
Te quedan 5 intentos.
Ingresa una letra: r
La palabra hasta el momento es: _ _ _ _ _ r
Adivinaste las siguientes letras: r
Te quedan 5 intentos.
Ingresa una letra: c
Si se ingresa una letra que no forma parte de la palabra, se pierde un intento.
La lista de palabras se debe leer de un archivo de texto, donde cada línea del archivo contendrá una palabra. De esa lista, se deberá elegir una palabra (puede ser una selección secuencial de palabras).
El programa termina cuando se adivina correctamente la palabra pensada, o cuando se acabaron los intentos.
Tips:
- Recuerda que las variables son inmutables por default. Para cambiar el estado de una variable, se la debe declarar como mut.
- Se puede comparar Strings usando: ==
- Usa println!(...) para imprimir elementos en la salida estándar. Para imprimir una variable, puedes escribir algo como esto:
#![allow(unused)] fn main() { println!("Contenido: {}", s); }
- Para leer de la entrada estándar, se puede usar algo como esto:
#![allow(unused)] fn main() { io::stdin() .read_line(&mut v) .expect("Error leyendo la linea."); }
Parte B
Mostrar las letras que se ingresaron y que no forman parte de la palabra (las que hacen que se pierda un intento).
Verificar si se ingresó nuevamente una letra que ya estaba.
Parte C
Sobre la implementación de las funciones, modelizar una estructura de datos que represente al tipo de error de retorno. Por ejemplo: se agotaron los intentos. Basarse en el enum Result.
Ejercicio 2 - Contar palabras
Escribir un programa para contar las frecuencias de palabras únicas leídas de un archivo de entrada. Luego imprimirlas con sus frecuencias, ordenadas primero por las más frecuentes. Por ejemplo, dado este archivo de entrada:
La casa tiene una ventana
La ventana fue defenestrada
El programa debe imprimir:
ventana -> 2
La -> 2
casa -> 1
tiene -> 1
una -> 1
fue -> 1
defenestrada -> 1
Una solución básica consiste en leer el archivo línea por línea, convertirlo a minúsculas, dividir cada línea en palabras y contar las frecuencias en un HashMap. Una vez hecho esto, convertir el HashMap en una lista de pares de palabras y cantidad y ordenarlas por cantidad (el más grande primero) y por último imprimirlos.
Se debe seguir las siguientes recomendaciones:
- Para separar en palabras, se debe considerar los espacios en blanco, ignorando los signos de puntuación.
- Si la frecuencia de dos palabras es la misma, no importa el orden en el que aparecen las dos palabras en la salida impresa.
- No leer el archivo completo en memoria, se puede ir procesando línea por línea, o en conjuntos de líneas. Sí se puede mantener en memoria el hashmap completo.
- Usar solamente las herramientas de la biblioteca std del lenguaje.
Para leer un archivo línea por línea, se puede utilizar el método read_line.
Ejercicio 3 - Buscador Full-text
La búsqueda de texto está en todos lados. Desde encontrar un mensaje en redes sociales, productos en portales de comercio electrónico, o cualquier otra cosa en la web a través de Google.
En este ejercicio, construiremos un motor de búsqueda sencillo que pueda buscar en millones de documentos y clasificarlos según su relevancia.
El primer paso consiste en la preparación de los datos. Necesitamos construir el conjunto de datos sobre el que realizaremos las búsquedas, denominado corpus. Este conjunto será un grupo de archivos de texto plano (txt) que puede generarse a partir de artículos de Internet. Cada archivo será un documento que estará identificado por un id.
Luego se debe realizar la indexación: Se debe implementar una estructura conocida como de índice invertido. Que será una estructura de datos de tipo HashMap que contendrá como clave cada una de las palabras y como valor, el o los ids de documentos en los que aparece la palabra. Para este paso, se debe realizar el proceso de tokenización, es decir, obtener cada una de los tokens que conforman al documento, considerando las separaciones de los mismos por espacios en blanco o saltos de línea, y quitando los signos de puntuación. De estos tokens, se debe ignorar las palabras más usadas del lenguaje español (conocidas como stop words), por ejemplo, los artículos: la, el, las, los. Se debe considerar la frecuencia de cada token, es decir, la cantidad de veces que el mismo aparece en el documento. Ese valor debe ser almacenado para el ordenamiento de los resultados.
El último paso es implementar la búsqueda. Para ello, se debe solicitar al usuario una frase a buscar y aplicar la tokenización de la misma y la eliminación de las stop words. Se debe buscar los documentos que contengan los términos de búsqueda ingresados.
Luego se debe determinar la relevancia de cada documento resultado de la búsqueda. Para esto, se debe determinar el puntaje del documento. Esto se puede computar a partir de sumar las frecuencias de cada uno de los términos encontrados.
Para mejorar el cálculo de puntaje del documento, calcularemos la frecuencia inversa de documentos para un término (denominado tf-idf) dividiendo la cantidad de documentos (N) en el índice por la cantidad de documentos que contienen el término, y tomaremos el logaritmo.
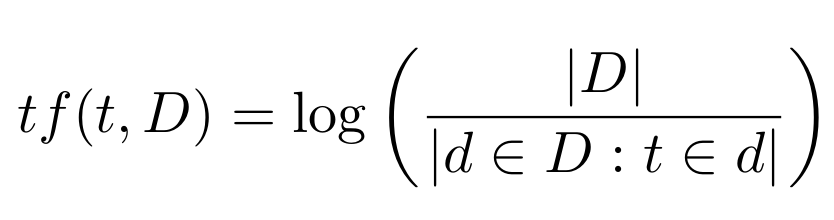
donde:
- |D| es la cantidad de documentos del corpus.
- |d ∈ D : t ∈ d| es el número de documentos donde aparece el término t. Si el término no está en la colección se producirá una división-por-cero. Por lo tanto, se suele ajustar esta fórmula a 1 + |d ∈ D : t ∈ d|
Luego, multiplicaremos la frecuencia del término con la frecuencia inversa del documento durante nuestra clasificación, por lo que las coincidencias en términos que son raros en el corpus contribuirán más a la puntuación de relevancia.
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución de los ejercicios:
- El proyecto deberá ser desarrollado en lenguaje Rust, usando las herramientas de la biblioteca estándar.
- No se permite utilizar crates externos. El único crate autorizado a ser utilizado es rand en caso de que se quiera generar valores aleatorios.
- El código fuente debe compilarse en la versión stable del compilador y no se permite utilizar bloques unsafe.
- El código deberá funcionar en ambiente Unix / Linux.
- El programa deberá ejecutarse en la línea de comandos.
- La compilación no debe arrojar warnings del compilador, ni del linter clippy.
- Las funciones y los tipos de datos (struct) deben estar documentadas siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- Las funciones no deben tener una extensión mayor a 30 líneas. Si se requiriera una extensión mayor, se deberá particionarla en varias funciones.
- Cada tipo de dato implementado debe ser colocado en una unidad de compilación (archivo fuente) independiente.
Guía de Ejercicios 2: Ownership en Rust
Ejercicio 1
Analizar las siguientes porciones de código y responder si el mismo compila o no. Explicar por qué sí o por qué no.
Si no se compila, ¿qué podrías cambiar para que compile?
fn main() { let mut s = String::from("hola"); let ref1 = &s; let ref2 = &ref1; let ref3 = &ref2; s = String::from("chau"); println!("{}", ref3.to_uppercase()); }
#![allow(unused)] fn main() { fn drip_drop() -> &String { let s = String::from("hello world!"); return &s; } }
fn main() { let s1 = String::from("hola"); let mut v = Vec::new(); v.push(s1); let s2: String = v[0]; println!("{}", s2); }
Ejercicio 2 - diff
Encontrar la diferencia entre dos archivos es un problema que es bastante conocido y estudiado.
La mayoría de las implementaciones usan el algoritmo de Myers, en este ejercicio, haremos que calcule la subsecuencia común más larga entre los dos archivos con el algoritmo LCS y use esa información para calcular su diferencia.
Este ejercicio se divide en hitos a cumplir.
Leer los dos archivos en dos vectores de líneas
En este hito, se debe implementar la función read_file_lines la cual debe tomar como parámetro la ruta al archivo y devolver un vector conteniendo las líneas del archivo.
Implementar el algoritmo LCS - Longest Common Subsequence
Longest Common Subsequence es un algoritmo conocido: dadas dos secuencias, ¿cuál es la subsecuencia más larga que aparece en ambas?
Si las secuencias de caracteres son a b c d y a d b c, la subsecuencia común más larga es a b c, porque estos caracteres aparecen en ambas secuencias en ese orden (notar que la subsecuencia no necesita ser consecutiva, sino que debe estar en orden).
Cuando se hace el diff entre dos archivos, queremos determinar cuáles línas deben ser agregadas o eliminadas entre ellos. Para lograr esto, necesitamos identificar las línas que son comunes entre ambos archivos. Esto se enmarca en lo que se conoce como un problema LCS -hay un buen video explicativo-: tenemos las dos secuencias de líneas y queremos encontrar la mayor subsecuencia de línas que aparecen en ambos archivos; estas líneas son la que no fueron modificadas y las otras líneas son las que fueron agregadas o eliminadas.
La solución incluye completar una grilla con los largos de subsecuencias. El siguiente es un fragmento de pseudocódigo que se puede usar como base para reimplementar en Rust:
#![allow(unused)] fn main() { let X and Y be sequences let m be the length of X, and let n be the length of Y C = grid(m+1, n+1) // recordar que .., es inclusivo para el límite inferior, pero excluye al superior for i := 0..m+1 C[i,0] = 0 for j := 0..n+1 C[0,j] = 0 for i := 0..m for j := 0..n if X[i] = Y[j] C[i+1,j+1] := C[i,j] + 1 else C[i+1,j+1] := max(C[i+1,j], C[i,j+1]) return C }
Usar el LCS para construir el diff
Implementar e invocar al siguiente pseudocódigo para imprimir el diff:
#![allow(unused)] fn main() { // C es la grilla computada por lcs() // X e Y son las secuencias // i y j especifican la ubicacion dentro de C que se quiere buscar cuando // se lee el diff. Al llamar a estar funcion inicialmente, pasarle // i=len(X) y j=len(Y) function print_diff(C, X, Y, i, j) if i > 0 and j > 0 and X[i-1] = Y[j-1] print_diff(C, X, Y, i-1, j-1) print " " + X[i-1] else if j > 0 and (i = 0 or C[i,j-1] >= C[i-1,j]) print_diff(C, X, Y, i, j-1) print "> " + Y[j-1] else if i > 0 and (j = 0 or C[i,j-1] < C[i-1,j]) print_diff(C, X, Y, i-1, j) print "< " + X[i-1] else print "" }
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución de los ejercicios:
- El proyecto deberá ser desarrollado en lenguaje Rust, usando las herramientas de la biblioteca estándar.
- No se permite utilizar crates externos. El único crate autorizado a ser utilizado es rand en caso de que se quiera generar valores aleatorios.
- El código fuente debe compilarse en la versión stable del compilador y no se permite utilizar bloques unsafe.
- El código deberá funcionar en ambiente Unix / Linux.
- El programa deberá ejecutarse en la línea de comandos.
- La compilación no debe arrojar warnings del compilador, ni del linter clippy.
- Las funciones y los tipos de datos (struct) deben estar documentadas siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- Las funciones no deben tener una extensión mayor a 30 líneas. Si se requiriera una extensión mayor, se deberá particionarla en varias funciones.
- Cada tipo de dato implementado debe ser colocado en una unidad de compilación (archivo fuente) independiente.
Guía de Ejercicios 3: Concurrencia en Rust
Ejercicio 1 - Cuentas bancarias
El fragmento de código 1 hace uso de unsafe para poder mutar una variable global. Esto introduce condiciones de carrera sobre los datos (data races) que provocan que el programa falle de manera imprevista al correrlo repetidas veces. Es decir, el problema se presenta en alguno de los posibles escenarios de ejecución.
Corregir el programa haciendo uso de las abstracciones que provee Rust para el manejo de la concurrencia de manera que no se produzcan errores.
use std::thread; struct Account(i32); impl Account { fn deposit(&mut self, amount: i32) { println!("op: deposit {}, available funds: {:?}", amount, self.0); self.0 += amount; } fn withdraw(&mut self, amount: i32) { println!("op: withdraw {}, available funds: {}", amount, self.0); if self.0 >= amount { self.0 -= amount; } else { panic!("Error: Insufficient funds.") } } fn balance(&self) -> i32 { self.0 } } static mut ACCOUNT: Account = Account(0); fn main() { let customer1_handle = thread::spawn(move || unsafe { ACCOUNT.deposit(40); }); let customer2_handle = thread::spawn(move || unsafe { ACCOUNT.withdraw(30); }); let customer3_handle = thread::spawn(move || unsafe { ACCOUNT.deposit(60); }); let customer4_handle = thread::spawn(move || unsafe { ACCOUNT.withdraw(70); }); let handles = vec![ customer1_handle, customer2_handle, customer3_handle, customer4_handle, ]; for handle in handles { handle.join().unwrap(); } let savings = unsafe { ACCOUNT.balance() }; println!("Balance: {:?}", savings); }
Ejercicio 2 - ThreadPool
Un threadpool mantiene varios hilos de ejecución (threads) en espera de que el programa supervisor asigne tareas para su ejecución simultánea. Al mantener un grupo de threads, el modelo aumenta el rendimiento y evita la latencia en la ejecución debido a la frecuente creación y destrucción de threads para tareas de corta duración.
En este ejercicio se debe armar un threadpool sencillo haciendo uso de las herramientas para computación concurrente que nos provee la biblioteca estándar de Rust.
Para distribuir las tareas a realizar entre los threads del pool se puede utilizar una cola concurrente.
Consideraciones a tener en cuenta:
- La estructura de datos utilizada para distribuir el trabajo.
- ¿Que se hace cuando una tarea enviada al threadpool provoca que un thread muera? Esta situación no debería afectar a otros threads. Ademas tras la muerte de un thread, se debe crear otro de forma de que la cantidad total de threads en el pool no cambie.
- Cuando la threadpool es terminada o sale de scope todos los threads deberian finalizar.
El fragmento de código 2 muestra un ejemplo de uso:
fn main() { let pool = ThreadPool::new(4); for i in 0..4 { pool.spawn(move || { std::thread::sleep(std::time::Duration::from_millis(250 * i)); println!("This is Task {}", i); }); } std::thread::sleep(std::time::Duration::from_secs(2)); }
Ejercicio 3 - Contar palabras concurrente
Escribir un programa, basado en el ejercicio 2 de la guía 1, para contar las frecuencias de palabras únicas leídas desde varios archivos de entrada.
La lectura y procesamiento de los archivos debe ser realizada de forma concurrente. Una vez finalizado el procesamiento de los mismos, imprimirlos con sus frecuencias, ordenados primero por las más frecuentes.
Realizar las siguientes implementaciones y comparar los tiempos de ejecución:
- Un mapa de resultados parciales por thread (por archivo), unir las sumas parciales al hacer join(), utilizando el valor de retorno de los hilos.
- Un mapa de resultados parciales por thread, enviar las sumas parciales de los threads utilizando channels.
- Un mapa de resultados globales accedidos por thread.
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución de los ejercicios:
- El proyecto deberá ser desarrollado en lenguaje Rust, usando las herramientas de la biblioteca estándar.
- No se permite utilizar crates externos. El único crate autorizado a ser utilizado es rand en caso de que se quiera generar valores aleatorios.
- El código fuente debe compilarse en la versión stable del compilador y no se permite utilizar bloques unsafe.
- El código deberá funcionar en ambiente Unix / Linux.
- El programa deberá ejecutarse en la línea de comandos.
- La compilación no debe arrojar warnings del compilador, ni del linter clippy.
- Las funciones y los tipos de datos (struct) deben estar documentadas siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- Las funciones no deben tener una extensión mayor a 30 líneas. Si se requiriera una extensión mayor, se deberá particionarla en varias funciones.
- Cada tipo de dato implementado debe ser colocado en una unidad de compilación (archivo fuente) independiente.
Guía de Ejercicios 4: Sockets en Rust
Ejercicio 1 - Introducción
Ítem A
Escribir un programa tal que el hilo main crea un thread hijo que actuará como cliente, mientras el padre actúa como servidor. La comunicación se establece para enviar y recibir un saludo, por ejemplo: Hola hijo y Buen día Papá.
Ítem B
Modificar el programa del ejercicio anterior para que el servidor pueda gestionar más de un cliente.
Ejercicio 2 - Mini Chat
Implementar un programa para armar una sala de chat.
El programa inicia y le pide un nickname al usuario. Luego, abre un socket servidor ligado a un puerto configurable. A continuación, realiza broadcasting del nickname a la subred, para después quedar escuchando mensajes.
Si recibe un mensaje de broadcast con un nickname, lo agrega a la lista de usuarios de la sala de chat, junto a la dirección IP de quien se lo envía.
Si recibe otro mensaje, se lo imprime por pantalla.
Para recibir un mensaje del usuario, se debe leer de la estrada estándar (stdin). Si se lo antecede con el nickname de destino, se lo envía a ese destinatario en particular. Con Enter, se transmite el mensaje.
Ejercicio 3 - FTP Honeypot
Introducción
Un honeypot es una aplicación que simula ser un servidor de otra aplicación mayor, para que cuando un usuario malicioso se conecte, ataque este servidor falso, permitiendo tomar registro de las técnicas de ataque que se utilizan en la red. En este trabajo práctico prototiparemos un honeypot de un servidor FTP.
Protocolo FTP
El protocolo FTP es un protocolo de texto, formado por mensajes delimitados por un salto de línea.
Los comandos son palabras en su mayoría de 4 letras, seguidos de un espacio que los separa de sus argumentos. El servidor responde con un código numérico y un texto descriptivo.
Cliente FTP
Los comandos que puede ejecutar el cliente son los siguientes
USER <username>: Envía un nombre de usuario para realizar login.PASS <password>: Envía un password para el usuario.SYST: Consulta información del sistemaLIST: Consulta los archivos contenidos en el directorio actualHELP: Consulta los comandos disponiblesPWD: Consulta el directorio actualMKD: Crea un directorioRMD: Elimina un directorio
Para simplificar el trabajo práctico, la transferencia de datos se realizará respondiendo en el mismo puerto por el cual se conectan inicialmente los clientes.
Esto implica que los comandos PASV y PORT no serán necesarios para transmitir información (por ejemplo con el comando LIST).
Servidor FTP
El servidor FTP responde con los siguientes mensajes:
- Cuando un cliente recién se conecta:
220 <newClient> - Cuando un cliente quiere operar sin haber hecho login:
530 <clientNotLogged> - Luego de que un cliente envía un comando
USER:331 <passRequired> - Si el usuario envía un comando que no es
PASSluego de un comandoUSER:530 <clientNotLogged> - Si el usuario realiza un login válido (el usuario enviado con
USERy la contraseña enviada conPASSson válidas, es decir, concuerdan con las configuradas):230 <loginSuccess> - Si el usuario realiza un login inválido:
530 <loginFailed>
Una vez que el cliente realizó un login exitoso, se habilitan varios comandos al cliente:
- Si el usuario envía el comando
SYST:215 <systemInfo> - Si el usuario envía el comando
HELP:214 <commands> - Si el usuario envía el comando
LIST, se realizará una respuesta en 3 partes
La primera línea será 150 <listBegin>
Luego enviará una línea por cada directorio cargado, con el siguiente formato:
drwxrwxrwx 0 1000 1000 4096 Sep 24 12:34 <nombre directorio>
Los directorios serán listados en orden alfabético.
Luego de enviar las líneas, enviará 226 <listEnd>.
- Si el usuario envía el comando
PWD:257 <currentDirectoryMsg> - Si el usuario envía el comando
MKD <nombreDir>, intenta agregar ````'' a la lista de directorios existentes responde: 257 "<nombreDir> <mkdSuccess>"en caso de que el directorio no existía.550 <mkdFailed>si ya existía
- Si el usuario envía el comando
RMD <nombreDir>intenta remover"<nombreDir>"de la lista de directorios y responde:250 <rmdSuccess>si el directorio existe.550 <rmdFailed>si no existía.
- Finalmente, el usuario puede pedirle al servidor que termine la conexión enviando la palabra
QUIT. En tal caso el servidor responde con221 <quitSuccess>y ambos cierran sus conexiones ordenadamente.
Cabe destacar que la entrada de comandos puede no terminar con QUIT, debiendo el cliente cerrar su conexión al llegar al final del stream y el servidor liberar sus recursos adecuadamente.
Configuración de mensajes
El servidor FTP lee un archivo de configuración las siguientes variables
user: Usuario para realizar loginpassword: Password para realizar loginnewClient: Mensaje enviado a un cliente recién conectadoclientNotLogged: Mensaje enviado a un cliente que quiere operar sin haber hecho loginpassRequired: Mensaje de solicitud de passwordloginSuccess: Mensaje de password aceptadologinFailed: Mensaje de password rechazadosystemInfo: Mensaje de información del sistemacommands: Mensaje con los comandos disponiblesunknownCommand: Mensaje de comando inválidoquit: Mensaje de desconexión del usuario
El archivo de configuración posee un formato ```clave=valor`'', y debe ser cargado al iniciar la aplicación. No se validará que se encuentren todas las claves necesarias, en caso de faltar una clave necesaria, es a decisión del desarrollador cómo contemplar este caso.
Formato de Línea de Comandos
Servidor
./server <puerto/servicio> <configuracion>
Donde <puerto/servicio> es el puerto TCP (o servicio) en donde estará escuchando la conexiones entrantes, <configuracion> el archivo con las variables del servidor.
Cliente
El cliente se ejecuta utilizando el siguiente formato de línea de comandos
./client <ip/hostname> <puerto/servicio>
El cliente se conectará al servidor corriendo en la máquina con dirección IP <ip> (o <hostname>), en el puerto (o servicio) TCP <puerto/servicio>.
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución de los ejercicios:
- El proyecto deberá ser desarrollado en lenguaje Rust, usando las herramientas de la biblioteca estándar.
- No se permite utilizar crates externos. El único crate autorizado a ser utilizado es rand en caso de que se quiera generar valores aleatorios.
- El código fuente debe compilarse en la versión stable del compilador y no se permite utilizar bloques unsafe.
- El código deberá funcionar en ambiente Unix / Linux.
- El programa deberá ejecutarse en la línea de comandos.
- La compilación no debe arrojar warnings del compilador, ni del linter clippy.
- Las funciones y los tipos de datos (struct) deben estar documentadas siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- Las funciones no deben tener una extensión mayor a 30 líneas. Si se requiriera una extensión mayor, se deberá particionarla en varias funciones.
- Cada tipo de dato implementado debe ser colocado en una unidad de compilación (archivo fuente) independiente.
MiniKV
Introducción
Los key–value stores (kvs) son una de las estructuras de persistencia más utilizadas en sistemas modernos, debido a su simplicidad, eficiencia y escalabilidad.
En este ejercicio se propone implementar un mini kvs persistente en Rust llamado minikv. El sistema permitirá almacenar pares clave–valor utilizando un archivo de log donde se registran todas las operaciones, además de soportar la creación de snapshots que permitan compactar el log.
Interfaz
El programa deberá ejecutarse mediante la línea de comandos, y soportará los siguientes comandos:
setgetlengthsnapshot
Comando set
Asocia un valor a una clave.
minikv set <clave> <valor>
Por ejemplo:
$ minikv set clave1 valor1
OK
$ minikv set clave2 valor2
OK
Si se omite el valor, entonces se desasocia el valor de la clave (unset).
$ minikv set clave2
OK
Comando get
Obtiene el valor asociado a una clave.
minikv get <clave>
Por ejemplo:
$ minikv get clave1
valor1
$ minikv get clave2
NOT FOUND
Comando length
Devuelve la cantidad de claves con valor.
minikv length
Por ejemplo:
$ minikv length
1
$ minikv set clave1
OK
$ minikv length
0
Comando snapshot
Genera un snapshot del estado actual y compacta el log.
minikv snapshot
Persistencia
El sistema utilizará dos archivos del directorio actual para persistir información:
.minikv.log.minikv.data
El log contiene todas las operaciones de escritura desde el último snapshot. Por ejemplo:
set clave1 valor1
set clave2 valor2
set clave2
set clave1
Al ser un append-only log, solo se tiene permitido escribir al final del log, sin modificar las operaciones previas.
El snapshot contiene el estado completo del store. Por ejemplo:
clave1 valor1
clave2 valor2
Para generar un snapshot, se deberá:
- Leer
.minikv.datasi existe y cargar los datos en memoria. - Leer
.minikv.logy aplicar secuencialmente todas las operaciones. - Persistir el estado completo nuevamente en
.minikv.data. - Truncar el log
.minikv.log.
Es muy importante que estos archivos respeten el formato indicado.
Restricciones
- No se permite que el programa lance un panic!(). Es decir, no se puede utilizar
.unwrap()o.expect(). Todo caso de error deberá manejarse idiomáticamente con las estructuras y funciones brindadas por el lenguaje. - No se permite utilizar la función exit(). Se deberá salir del programa finalizando el scope de la función
main. - No se permite utilizar el módulo mem para la manipulación de memoria.
- Para realizar un uso adecuado de memoria y respetar las reglas de ownership se deberá evitar el uso de .clone() y .copy() en las estructuras principales de datos.
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución del proyecto:
- El proyecto deberá ser desarrollado en la última versión estable de Rust (1.94), usando las herramientas de la biblioteca estándar.
- Se deben implementar tests unitarios.
- No se permite utilizar crates externos.
- El código fuente debe compilarse en la versión estable del compilador.
- No se permite utilizar bloques
unsafe. - El código deberá funcionar en ambiente Unix / Linux.
- Los programas deberán ejecutarse en la línea de comandos.
- La compilación no debe arrojar
warningsdel compilador, ni del linterclippy. - Las funciones y los tipos de datos (
struct,enum) deben estar documentados siguiendo el estándar decargo doc. - El código debe formatearse utilizando
cargo fmt. - Las funciones no deben tener una extensión mayor a 30 líneas. Si se requiriera una extensión mayor, se deberá particionarla en varias funciones.
- Cada tipo de dato implementado debe ser colocado en un módulo (archivo) independiente.
El proyecto deberá realizarse de manera individual. Cualquier tipo de copia significa la expulsión automática de la materia. No está permitido el uso de código generado por ninguna IA, ni copiar código de soluciones existentes en Internet.
Entrega
Fecha de entrega: 23/3 - 18:00
La entrega se realizará por Algotron. Para que la entrega se considere válida, deberán pasar todas las verificaciones de la plataforma. En caso contrario, no se podrá continuar en la materia.
MiniKV Server
Introducción
La arquitectura cliente-servidor es la predominante en la internet debido a su capacidad para centralizar recursos, mejorar la seguridad y gestionar datos de forma eficiente. Permite que múltiples usuarios (clientes) accedan simultáneamente a servicios, bases de datos o aplicaciones compartidas alojadas en una máquina central (servidor), facilitando el mantenimiento, la escalabilidad y la organización de la información.
En este ejercicio se propone implementar un servidor de base de datos en Rust llamado minikv-server. El sistema permitirá a múltiples clientes operar sobre la misma base de datos minikv desarrollada previamente. La comunicación se realizará mediante sockets. Desde el lado del servidor, cada conexión se procesará en un thread distinto.
Para más información sobre concurrencia en Rust, referirse a The Rust Programming Language - Capítulo 16. Como ejemplo de un proyecto que utiliza concurrencia y redes, pueden leer The Rust Programming Language - Capítulo 21.
Binarios Entregables
El proyecto de Rust deberá estar compuesto por dos binarios:
minikv-serverminikv-client
Para más información sobre cómo estructurar el proyecto, referirse The Rust Programming Language - Capítulo 7.
Para validar que el proyecto está bien estructurado, ejecutar cargo build deberá generar dos binarios, uno con el nombre de minikv-server, y otro con el nombre de minikv-client.
Servidor
El servidor recibirá como argumento la dirección a través de la cual escuchará conexiones entrantes de los operadores.
cargo run --bin minikv-server -- 192.168.0.0:12345
Al iniciar, el servidor tiene que leer el estado de .minikv.data y el .minikv.log para construir la base de datos en memoria. Se debe persistir el estado a medida que se ejecuten los comandos.
Por cada conexión entrante, el servidor debe crear un hilo nuevo para manejar esa conexión.
Cliente
El cliente recibirá como argumento la dirección del servidor, y leerá las operaciones a enviar al servidor a través de STDIN.
cargo run --bin minikv-client -- 192.168.0.0:12345
El cliente deberá establecer una conexión con el servidor, y enviar las operaciones secuencialmente. No se debe validar que las operaciones sean válidas, eso es trabajo del servidor. El resultado de las operaciones deberá imprimirse por STDOUT.
Ejemplo:
stdin : set a b
stdout : OK
stdin : get a
stdout : b
stdin : set c d
stdout : OK
stdin : snapshot
stdout : OK
Deben existir timeouts para que el programa no quede colgado esperando al server, y estos deben ser constantes configurables.
Errores
Los casos de error se dividen en 3 categorías:
- Error de cliente
- Error de comunicacion
- Error del servidor
Los errores se imprimirán por STDOUT, y deberán respetar el siguiente formato.
ERROR "<motivo>"
Errores de cliente
Estos errores son recuperables, es decir que puede continuar la ejecución del programa servidor y la comunicación entre cliente y servidor. Cuando el servidor los detecta se debe enviar el error al cliente en el formato especificado, pero manteniendo la conexión activa.
Los códigos de error son:
NOT FOUNDEXTRA ARGUMENTMISSING ARGUMENTUNKNOWN COMMAND
Errores de comunicacion
Estos implican el cierre de la comunicación con el cliente pero no afectan la ejecución del programa servidor. Como no puede comunicarse el error con el cliente se deberá manejar por separado en ambos programas:
- En el server se debe imprimir el error en el formato especificado, y finalizar ese hilo, pero NO el servidor completo.
- En el cliente se debe imprimir el error, y finalizar la ejecución.
Los códigos de error son:
TIMEOUT: El server tarda demasiado en contestar, lo cual puede indicar que está caído.CONNECTION CLOSED: La conexión se cierra de forma repentina.CLIENT SOCKET BINDING: El cliente no puede bindear un socket en la dirección especificada del server.
Errores del server
Estos errores son irrecuperables e implican la finalización del programa servidor
Los códigos de error son:
INVALID ARGS: No se reciben los argumentos esperados en la ejecución del server.SERVER SOCKET BINDING: El servidor no puede bindear un socket en la dirección especificada.INVALID DATA FILEINVALID LOG FILE
Operaciones
Las operaciones que admite el servidor son las siguientes:
setgetlengthsnapshot
Los comandos siguen la misma lógica que en la entrega anterior.
Protocolo de Comunicación
El protocolo de comunicación será sencillo. El cliente y servidor intercambiarán mensajes de texto. Para más información, ver text-based protocols.
El protocolo permitirá enviar los comandos definidos. Al recibir el mensaje el servidor ejecutará el comando y responderá con el output del comando.
Ejemplo 1
Consideramos un único servidor, y un único cliente.
client : set a b
server : OK
client : get a
server : b
client : set c d
server : OK
client : snapshot
server : OK
Ejemplo 2
En caso de una operación inválida, respondemos con un mensaje de error e ignoramos la operación.
client : set a b
server : OK
client : set a b c
server : ERROR "EXTRA ARGUMENT"
client : get a
server : b
Ejemplo 3
En el caso de múltiples clientes vamos a poder tener operaciones intercaladas, por ejemplo
client1 : set a b
server : OK
client2 : set a c
server : OK
client1 : get a
server : c
Restricciones
- No se permite que el programa lance un panic!(). Es decir, no se puede utilizar
.unwrap()o.expect(). Todo caso de error deberá manejarse idiomáticamente con las estructuras y funciones brindadas por el lenguaje. - No se permite utilizar la función exit(). Se deberá salir del programa finalizando el scope de la función
main. - No se permite utilizar el módulo mem para la manipulación de memoria.
- Para realizar un uso adecuado de memoria y respetar las reglas de ownership se deberá evitar el uso de .clone() y .copy() en las estructuras principales de datos.
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución del proyecto:
- El proyecto deberá ser desarrollado en la última versión estable de Rust (1.94), usando las herramientas de la biblioteca estándar.
- Se deben implementar tests unitarios.
- No se permite utilizar crates externos.
- El código fuente debe compilarse en la versión estable del compilador.
- No se permite utilizar bloques
unsafe. - El código deberá funcionar en ambiente Unix / Linux.
- Los programas deberán ejecutarse en la línea de comandos.
- La compilación no debe arrojar
warningsdel compilador, ni del linterclippy. - Las funciones y los tipos de datos (
struct,enum) deben estar documentados siguiendo el estándar de cargo doc. - El código debe formatearse utilizando
cargo fmt. - Las funciones no deben tener una extensión mayor a 30 líneas. Si se requiriera una extensión mayor, se deberá particionarla en varias funciones.
- Cada tipo de dato implementado debe ser colocado en un módulo (archivo) independiente.
- No debe existir un busy loop.
El proyecto deberá realizarse de manera individual. Cualquier tipo de copia significa la expulsión automática de la materia. No está permitido el uso de código generado por ninguna IA, ni copiar código de soluciones existentes en Internet.
Entrega
Fecha de entrega: 09/04 - 18:00
La entrega se realizará por Algotron. Para que la entrega se considere válida, deberán pasar todas las verificaciones de la plataforma. En caso contrario, no se podrá continuar en la materia.
Proyecto - 1C 2026
Propuesta de Proyecto
A continuación, se detallan las secciones que deben ser incluidas en el documento de propuesta de proyecto.
Estructura del documento
- Carátula
- Resumen/Abstract
- Palabras clave/Keywords
- Introducción
- Estado del Arte
- Problema detectado y/o faltante
- Solución propuesta
- Evaluación preliminar de impacto social y ambiental
- Metodología
- Experimentación, validación, control de calidad
- Plan de actividades
- Anexos
En los próximos párrafos se detallará el contenido de cada una de las secciones.
Carátula
La carátula debe incluir el logo de la Facultad de Ingeniería, el título de la propuesta, los nombres, apellidos, emails y legajos de los estudiantes.
Como el título del trabajo orienta a los lectores respecto de qué se trata el mismo, se recomienda, una vez escrita la propuesta, releer el título y evaluar cuánto se ajusta al documento final.
Resumen / Abstract
Se trata de una breve descripción del trabajo, en español e inglés.
Este apartado debe escribirse una vez que se escribió el resto del documento y es un resumen de todo el documento. Se coloca al principio porque es lo primero que lee quien quiere saber de qué se trata el proyecto. No deberá tener más de 3 o 4 párrafos.
Palabras clave / Keywords
Conjunto de palabras que permiten catalogar al trabajo tanto sea en inglés como en español. Pueden ser entre 5 y 10 palabras o frases cortas.
Introducción
Breve reseña de las partes con la que cuenta el presente documento y se presenta el problema y/o servicio a mejorar y/o resolver. Es el punto de partida para presentar el proyecto: se debe ser preciso y enfocado en el objetivo del proyecto.
Estado del Arte
En esta sección se hace un breve mapeo documental de los avances relacionados a la aplicación a desarrollar y es la base para demostrar la validez del proyecto. Aquí se remarca que, al ser un proyecto intermedio, de carácter integrador, el mismo debe ser innovador y encontrarse en el estado del arte de la ingeniería.
Problema detectado y/o faltante
En esta sección se debe presentar el problema detectado y/o oportunidad de mejora relacionada con la construcción de la aplicación presentada. La misma debe ser redactada de manera clara y concisa, debe ser entendida en la primera lectura. Este ítem es de fundamental importancia al momento de ser evaluado el proyecto.
Solución propuesta
En esta sección se presenta una breve descripción de la solución que se propone. El principal objetivo de esta sección es poder dar el bosquejo de la solución para que pueda ser evaluado. No es necesario explicitar todos los detalles, pero sí mencionar sus componentes generales.
Importante: La solución propuesta deberá contar con al menos los siguientes componentes:
- Servicio backend
- Frontend / Aplicación gráfica
También se deberá enumerar las bibliotecas (crates) que se planean utilizar y explicar qué consideraciones se tuvieron en cuenta a la hora de elegirlas, tras discutirlo con la cátedra.
Importante: La solución propuesta deberá ser aprobada tanto por la cátedra como por el cliente asignado.
Evaluación preliminar de impacto económico, social y ambiental
Los proyectos de ingeniería, incluyendo los de Ingeniería en Informática, suelen tener impactos económicos, sociales y/o ambientales. En la propuesta se debe incluir un análisis preliminar de impacto, de carácter descriptivo solamente, y con los conocimientos que se tengan en el momento de realizar la misma.
Metodología de trabajo
Esta sección se usará para explicitar la metodología general de trabajo en el proyecto, incluyendo los roles de los ayudantes de la cátedra y los estudiantes.
Como el proyecto va a incluir el desarrollo de un producto, sea de software o un sistema de software-hardware (sistemas embebidos o ciberfísicos), se debe usar esta sección también para especificar el proceso de desarrollo del producto.
Deben tenerse en cuenta las siguientes pautas definidas en el reglamento de la asignatura:
- El método de desarrollo debe ser incremental, sea porque se desarrolla en iteraciones o bajo una modalidad de entrega continua. En cualquier caso, debe definir entregables intermedios y una cadencia de prácticas de seguimiento y mejora continua.
- Las tareas de desarrollo, prueba y despliegue que se puedan automatizar, deben estar automatizadas.
- Debe utilizarse alguna herramienta de versionado de código y de todos los artefactos que requieran versionarse (por ejemplo, configuraciones).
- Debe utilizarse alguna herramienta de calidad profesional para gestionar el proceso de desarrollo, el seguimiento de tickets y bugs, etc.
- Deben manejarse criterios de aceptación de entregas y pruebas de aceptación de las funcionalidades requeridas.
Si hay cuestiones metodológicas no definidas a esta altura, explicitarlo y explicar brevemente de qué depende la decisión.
Como todo proyecto tiene riesgos, deberá haber una lista de los riesgos iniciales del proyecto.
Experimentación, validación, control de calidad
Aquí se debe definir la estrategia de pruebas en detalle, incluyendo una descripción de herramientas a utilizar, tipos de pruebas y grado de automatización, qué roles habrá para ejecutar (en caso de que sean manuales) y/o especificar (en caso de que sean automatizadas) las pruebas. El conjunto de pruebas serán entregadas como resultado final del proyecto y verificación del mismo. En esta instancia se entrega el plan de validación, que podrá ser ajustado más adelante.
Plan de actividades
En esta sección se debe definir todo el proceso de construcción del producto, elegir metodología de trabajo, entregables, hitos de avance, pruebas de código, etc. Se debe explicar la metodología elegida y su adaptación al trabajo particular. En la descripción de la metodología se debe incluir una descripción de cómo se gestiona el alcance, tiempos, estimaciones, indicadores, riesgos, calidad, reuniones dentro del equipo y con los interesados. Se hace especial hincapié en el hecho de la documentación del sistema en cuestión, incluyendo documentación técnica de entregables, documentación funcional y de diseño, minutas de reuniones, etc.
Anexos
En caso de ser necesario agregar toda información relevante en uno o varios anexos.
Fecha de entrega
23 de abril de 2026.
Agregado Final 2C 2024: Containerization
Introducción
Containerization es un enfoque de virtualización que permite ejecutar aplicaciones en entornos aislados llamados contenedores. A diferencia de las máquinas virtuales tradicionales, que requieren un sistema operativo completo para cada instancia, los contenedores comparten el mismo núcleo del sistema operativo, lo que los hace más ligeros y eficientes en términos de recursos.
Docker
Docker es una plataforma de software que permite crear, implementar y ejecutar aplicaciones en contenedores, empaquetando el código de la aplicación junto con todas sus dependencias, bibliotecas y configuraciones necesarias para que funcione correctamente.
Objetivo
El objetivo principal es facilitar el posterior despliegue por parte de los clientes, haciendo foco en una transición fluida de la administración de la aplicación. Se opta por un formato estandar como entregable ya que asegura la existencia de multiples herramientas de despliegue que trabajan con este formato, permitiendo flexibilidad y portabilidad. Se busca tambien brindar visibilidad del estado de la aplicacion con la incorporacion del modulo de loggeo, que permitira a los clientes encontrar errores y arreglarlos en el futuro.
Requerimientos funcionales
Docker
Se deberán generar todos los artefactos necesarios para el deployment del proyecto utilizando Docker. Incluyendo la generación de imágenes, containers, recursos y configuraciones necesarias para la ejecución del proyecto. Como mínimo se deberán incluir en la entrega los siguientes artefactos: 1.Archivo de configuracin: Separar del código fuente todas las variables configurables, incluyendo secretos y parámetros de entorno en un archivo de configuracion. 2. Dockerfile: para la generación de la imágen de cada uno de los componentes. 3. Docker-compose: para la definición de todos los contenedores de la red, incluyendo sus configuraciones y recursos necesarios. 4. Todos los comandos necesarios para construir, iniciar, detener y destruir el proyecto. 5. Agregar un archivo README en la carpeta raíz del repositorio indicando todas las instrucciones para construir, iniciar, detener y destruir el ambiente, incluyendo todos las variable necesarias para funcionar.
Logger
De manera de poder visualizar facilmente el funcionamiento del sistema en Docker se pide implementar un Logger que registre los eventos relevantes. Dicho logger deberá poder escribir en un archivo y en la salida estándar (stdout) al mismo tiempo, de manera de poder visualizar el log utilizando el comando: docker logs.
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución del proyecto:
- El proyecto deberá ser desarrollado en lenguaje Rust, utilizando las herramientas de la biblioteca estándar.
- Se deben implementar pruebas unitarias y de integración de las funcionalidades que se consideren más importantes.
- El código fuente debe compilar en la versión estable del compilador y no se permite el uso de bloques inseguros (unsafe).
- El código deberá funcionar en ambiente Unix / Linux.
- La compilación no debe generar advertencias del compilador ni del linter clippy.
- El programa no puede contener ningún Busy-Wait, ni puede consumir recursos de CPU y/o memoria indiscriminadamente. Se debe hacer un uso adecuado tanto de la memoria como del CPU.
- Las funciones y los tipos de datos (struct) deben estar documentados siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- Las funciones no deben tener una extensión mayor a 30 líneas. Si se requiere una extensión mayor, se debe particionar en varias funciones.
- Cada tipo de dato implementado debe ser colocado en una unidad de compilación (archivo fuente) independiente.
Presentación
Se deberá realizar una presentación explicando la implementación de esta nueva consigna, incluyendo las decisiones de diseño y una demostración de la funcionalidad en vivo. Dentro de los detalles de implementación se deberá explicar la solución adoptada desde el punto de vista de multi-threading, con diagramas que faciliten la explicación. Durante la demostración en vivo, se debe poder observar tanto los requerimientos funcionales solicitados en el presente enunciado, como así también los requerimientos no funcionales. De la misma manera se deberá demostrar como se construyen todos los contenedores utilizando Docker y explicando los correspondientes comandos de Docker empleados.
Informe final
Solo se podrán presentar a la fecha de final teniendo completo el informe final completo del proyecto desarrollado durante el cuatrimestre. La seccion de solucion propuesta y plan de actividades debe reflejar el trabajo realizado para el examen final.
Fechas de final
El grupo deberá presentarse en una de las fechas de examen final, tal como se publica en el calendario respectivo. Las fechas de final para el cuatrimestre actual son:
- Lunes 29/6
- Lunes 13/7
- Lunes 27/7
- Lunes 3/8
- Lunes 10/8
Proyectos Realizados
2026
2025
2024
2023
2022
2021
Proyecto: RoomRTC - 2C 2025
Introducción
Desde la pandemia de COVID-19 en 2020, el software para videoconferencias cobra una importancia central, ya que posibilitó la realización de clases, congresos y diversos eventos de manera remota. Aun hoy, 5 años después, este tipo de sistemas sigue en vigencia.
En este contexto, la Universidad de Buenos Aires desea implementar un sistema de videoconferencias para transmitir cursos, congresos, etc. Para que un software de este tipo sea considerado de calidad, se requiere que cumpla con ciertos requisitos tanto funcionales como no funcionales, como podrían ser: Usabilidad, escalabilidad, velocidad, bajo consumo de red, confiabilidad, seguridad, entre otros.
Tras analizar las diferentes alternativas existentes, tanto en software libre como alternativas privativas, se decide implementar una solución in-house.
La misma deberá contar con una implementación propia de WebRTC. Siendo esta una serie de protocolos que permiten la transmisión de video y sonido en tiempo real por parte de navegadores y aplicaciones móviles. Debido a las necesidades de eficiencia y seguridad propias de este tipo de aplicaciones, el lenguaje de implementación será Rust.
Objetivo del proyecto
El objetivo principal del presente Trabajo Práctico es desarrollar una versión en el lenguaje Rust del stack WebRTC, de manera tal que sea posible la realización de videoconferencias entre usuarios en distintos dispositivos. El proyecto debe respetar las specs (i.e., especificaciones), haciendo énfasis en la compatibilidad con clientes existentes de WebRTC. Aspectos no funcionales como la escalabilidad y la eficiencia de la solución deben ser contemplados, ya que el proyecto debe poder ser utilizado por un gran número de personas, desde dispositivos de diversa potencia.
El objetivo secundario es desarrollar un proyecto real de software de mediana envergadura aplicando buenas prácticas de desarrollo, incluyendo entregas y revisiones periódicas. La idea es, después de todo, que este proyecto signifique no solo la aplicación de los temas vistos en la asignatura, sino que, del conjunto de conocimientos aprendidos durante la carrera hasta el momento.
Requerimientos funcionales
Un sistema basado en WebRTC consta de diversos componentes, por lo que será necesaria una planificación y división adecuada del trabajo.
Entre esas componentes podemos encontrar:
- SDP (Session Description Protocol): Utilizado para establecer la conexión entre pares.
- ICE (Interactive Connectivity Establishment): Protocolo de comunicación utilizado para definir la ruta por la que se enviará el video.
- Se debe soportar direcciones del tipo Host y Server reflexive (STUN). Para STUN se puede utilizar un servidor público.
- RTP(real-time transport protocol) y RTCP(RTP control protocol): Protocolo para realizar la transmisión de video.
- Signaling Server: Encargado del discovery de peers. En este caso, el servidor central actuará de signaling server.
- Además, a la hora de transmitir video y sonido, se puede utilizar una variedad de códecs como VP8 y H264 que son los encontrados en la mayoría de implementaciones del protocolo. Pero a nivel de especificación, WebRTC no limita qué códec se debe utilizar, siempre y cuando ambas partes de la conexión se pongan de acuerdo.
Servidor central
Se deberá contar con un servidor central que actúe de signaling server y que cumpla con las siguientes características:
- Manejo de usuarios
- Persistir en un archivo en texto plano a los usuarios de la plataforma junto con su contraseña y cualquier información que consideren relevante. No es necesario que esté encriptado.
- Un usuario se debe poder registrar.
- Un usuario debe poder hacer un log in en la plataforma.
- El mismo usuario no puede estar conectado dos veces en la plataforma.
- Obtener el listado de usuarios y sus estados.
- Los usuarios pueden estar en uno de tres estados.
- Desconectado: El usuario está presente en la plataforma, pero no está conectado.
- Disponible: El usuario está conectado y está disponible para hacer una llamada.
- Ocupado: El usuario está actualmente en una llamada.
- Los usuarios pueden estar en uno de tres estados.
- Se debe poder llamar a un usuario disponible.
- Se deben poder soportar múltiples llamadas concurrentes entre distintos usuarios.
- Se debe poder limitar la cantidad de clientes simultaneos que pueden estar conectados a la aplicación.
Conexión con el servidor
La manera en la que los usuarios se van a comunicar con el servidor central va a ser a través de una conexión TCP encriptada con TLS o encriptando los mensajes ustedes mismos.
El protocolo a utilizar dentro de esta conexión debe ser definido por ustedes y estar completamente documentado, así como debe ser capaz de cumplir con todos los requerimientos de la plataforma.
La conexión entre el servidor y los usuarios debe ser persistente, por lo que mientras el programa esté activo debería tener una conexión viva con el servidor, de manera de que este le pueda enviar a los usuarios actualizaciones instantaneas acerca del estado de los usuarios conectados, así como también notificarte cuando un usuario te está ofreciendo hacer una llamada.
Seguridad
Una vez establecida la conexión entre 2 pares, la misma deberá realizarse sobre SRTP, la cual se inicializa con DTLS, para tener un canal de comunicación seguro.
Aplicación cliente
Funcionalidades mínimas:
- Registrarse e iniciar/cerrar sesión en la aplicación.
- Pedir usuarios de la plataforma con sus estados.
- Llamar a otro usuario que esté disponible.
- Aceptar una llamada propuesta por otro usuario.
- Salir de una llamada.
Flujo General
- Usuario2 se comunica con el servicio central para iniciar sesión.
- El servidor central cambia el estado del Usuario2 en la plataforma a disponible.
- El servicio central muestra el listado de usuarios con sus estados y la aplicación lo muestra en el "lobby".
- Usuario1 ve que Usuario2 está disponible. Decide llamarlo.
- Usuario2 tiene la opción de aceptar o declinar la llamada.
- Si se declina la llamada entonces se le notifica al Usuario1 y no pasa nada.
- Si se acepta la llamada se sigue con el flujo.
- Una vez aceptada la llamada, los usuarios intercambian oferta y respuesta SDP en el servidor.
- A partir de este punto, los usuarios aparecen como ocupados en la plataforma, pero siguen conectados al servidor. Pasan a hacer la llamada peer to peer, pasando a la siguiente etapa.
- Si alguno de los usuarios termina la llamada, ambos vuelven al lobby y aparecen como disponibles de nuevo.

Transmisión de video
La transmisión de video se realiza a través de RTP y RTCP.
Los paquetes que se tienen que implementar de RTCP son el paquete de bye y los sender y receiver reports. Se tienen que mostrar los valores que se manejan con los reportes en algún lugar de la UI mientras se van actualizando.
La transmisión de video tiene que cumplir con los siguientes requerimientos:
- La calidad esperada de video es 30fps, 720p.
- En el flujo de captura, transmisión y recepción de video, se espera que se paralelicen tareas para mayor eficiencia. Se pueden por ejemplo tener hilos para decodificar, codificar, empaquetar, etc. El diseño de una solución eficiente se evaluará en las entregas, por lo que lo tendrán que detallar en sus informes y presentar en las entregas.
- Se tienen que manejar la perdida y el desordenamiento de paquetes, sin delegárselo completamente a crates como openh264. La comunicación es en tiempo real, por lo que hay algunas cosas como pedir paquetes que se perdieron que no es necesario hacer, pero hay que notar cuando llegan en desorden, y descartar los que llegan muy tarde / no llegan. Tienen que tener en cuenta casos borde y explicarlos en sus informes así como presentaciones. Se espera que entiendan completamente el flujo de codificación y decodificación de video que eligieron y que manejen caminos no felices.
- Tener un jitter buffer para mitigar las fluctuaciones de la red. Tener en cuenta los timestamps de los frames para saber cuando mostrarlos, no simplemente mostrar cada frame apenas te llega.
Archivo de configuración
Cada componente deber poder ser configurado mediante un archivo de configuración, de extensión .conf y cuya ubicación se pasara por argumento de línea de comando: $ ./room-rtc /path/to/file.conf. Todos los valores de configuracion mencionados en este enunciado y cualquier otro parametro necesario para la ejecucion del programa debera estar definido en este archivo. No se permite definir valores hardcodeados en el codigo fuente, ya sean direcciones IP, puertos o cualquier otra informacion necesaria.
Logs
Cada componente deberá mantener un registro de las acciones realizadas y los eventos ocurridos en un archivo de log. La ubicación del archivo de log estará especificada en el archivo de configuración. Como requerimiento particular del Proyecto, NO se considerará válido que el servidor mantenga un file handle global, aunque esté protegido por un lock, y que se escriba directamente al file handle.
Es muy importante que al elegir lo que se va a loguear, se tenga en cuenta que en las entregas muchas veces los logs serán la única forma en la que sabremos lo que sucede en nuestro programa, por lo que tienen que ser claros y mostrar al docente que las cosas funcionan.
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución del proyecto:
- El proyecto deberá ser desarrollado en lenguaje Rust, utilizando las herramientas de la biblioteca estándar.
- Se deben implementar pruebas unitarias y de integración de las funcionalidades que se consideren más importantes.
- El código fuente debe compilar en la versión estable del compilador y no se permite el uso de bloques inseguros (unsafe).
- El código deberá funcionar en ambiente Unix/Linux.
- La compilación no debe generar advertencias del compilador ni del linter Clippy.
- El programa no puede contener ningún busy-wait, ni puede consumir recursos de CPU y/o memoria indiscriminadamente. Se debe hacer un uso adecuado tanto de la memoria como del CPU.
- Las funciones y los tipos de datos (struct) deben estar documentados siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- Las funciones no deben tener una extensión mayor a 30 líneas. Si se requiere una extensión mayor, se debe particionar en varias funciones.
- Cada tipo de dato implementado debe ser colocado en un módulo (archivo fuente) independiente.
Crates externos permitidos
Se permite el uso de los siguientes crates solo para los usos mencionados (siempre y cuando se los considere necesarios):
- rand: para la generación de valores aleatorios.
- chrono: para la obtención del timestamp actual.
- Crates para DTLS.
- Crates para la captura y procesamiento de video (como OpenCV o Nokhwa.
- Crates de códecs de media (VP8, H264, etc.).
- Crates para la implementación de la interfaz gráfica.
Importante: Cada crate externo que se desee utilizar para DLTS, captura y procesamiento de video e implementación de la interfaz gráfica deberá ser propuesto a los tutores, los cuales serán evaluados y autorizados por el grupo docente.
Material de consulta
- webrtc.org - Página oficial, contiene explicaciones tanto de alto nivel como detalles de implementación y de los diferentes componentes de WebRTC.
- WebRTC for the curious: Sitio con explicaciones alternativas sobre cada componente de WebRTC.
- WebRTC architecture: Contiene bastantes diagramas arquitecturales de los componentes del protocolo. — What is ICE?: Contiene diagramas y una buena explicación sobre ICE.
- OpenCV tutorial: video explicativo sobre cómo usar OpenCV desde Rust.
Criterios de Aceptación y Corrección del Proyecto
Para el desarrollo del proyecto, se deberán observar los siguientes lineamientos generales:
- Testing: Se deberá implementar testing unitario automatizado, utilizando las herramientas de Rust de los métodos y funciones relevantes implementados. Se deberán implementar tests de integración automatizados.
- Manejo de errores: Deberá hacerse un buen uso y administración de los casos de error, utilizando para ello las estructuras y herramientas del lenguaje, escribiendo en forma lo más idiomática posible su tratamiento.
- Control de versiones: Se deberá utilizar la herramienta git, siguiendo las recomendaciones de la cátedra. En particular, se deberá utilizar la metodología GitHub Flow para el trabajo con ramas (branches) y la entrega continua del software.
- Trabajo en equipo: Se deberá adecuar, organizar y coordinar el trabajo del equipo, realizando tareas como revisión de código cruzada entre pares de una funcionalidad en un pull request de git.
- Merge de branches: Para poder hacer el merge de un branch de una funcionalidad, todos los tests pasan de forma satisfactoria.
- Informe final: El trabajo debe acompañarse por un informe que debe incluir diagramas de secuencia de las operaciones más relevantes, diagrama de componentes y módulos de la arquitectura general del diseño desarrollado, todos acompañados de la explicación respectiva.
Evaluación
El desarrollo del proyecto tendrá un seguimiento directo semanal por parte del docente a cargo del grupo.
Se deberá desarrollar y presentar los avances y progreso del trabajo semana a semana (simulando un sprint de trabajo). Cada semana, cada docente realizará una valoración del estado del trabajo del grupo.
El progreso de cada semana deberá ser acorde a lo que se convenga con el docente para cada sprint. Si el mismo NO cumple con la cantidad de trabajo requerido, el grupo podrá estar desaprobado de forma prematura de la materia, a consideración del docente.
Hacia la mitad del desarrollo del proyecto se deberá entregar una versión preliminar que deberá cumplir con los requisitos mencionados en el apartado Entrega intermedia. Estos requisitos son de cumplimiento mínimo y obligatorio; aquellos grupos que lo deseen podrán implementar requisitos adicionales.
Nota importante: Se deja constancia de que las funcionalidades requeridas por este enunciado son un marco de cumplimiento mínimo y que puede haber agregados o modificaciones durante el transcurso del desarrollo por parte del docente a cargo, que formarán parte de los requerimientos a cumplir. Cabe mencionar que estos desvíos de los requerimientos iniciales se presentan en situaciones reales de trabajo con clientes.
Finalización del proyecto
El desarrollo del proyecto finaliza el último día de clases del cuatrimestre. En esa fecha, cada grupo deberá realizar una presentación final y se hará una evaluación global del trabajo.
En dicha presentación se deberá detallar la arquitectura del proyecto, aprendizajes del mismo, y realizar una muestra funcional del desarrollo; esto es una "demo" como si fuera para el usuario final, donde se pueda observar todas las funcionalidades pedidas por el presente enunciado.
Durante la demostración en vivo, se debe poder observar tanto los requerimientos funcionales solicitados en el presente enunciado, como así también los requerimientos no funcionales.
El trabajo debe acompañarse por un informe que debe constar de los puntos detallados a continuación: explicación general de la investigación realizada y sus conclusiones, reglas de negocio de la solución y decisiones tomadas durante el desarrollo del proyecto, diagramas de secuencia de las operaciones más relevantes, diagrama de componentes y módulos de la arquitectura general del diseño desarrollado, todos acompañados de la explicación respectiva.
Entrega intermedia:
Los alumnos deberán realizar una entrega intermedia, la cual deberá incluir los siguientes puntos del apartado de requerimientos funcionales:
SDP
Se deberá contar con la implementación de las estructuras de datos y los métodos necesarios para poder generar y parsear archivos SDP.
ICE
Los clientes deberán poder realizar la selección de candidatos y los connectivity checks para elegir la mejor ruta de comunicación entre pares siguiendo el protocolo de ICE.
Para esta entrega los candidatos pueden ser solo locales.
RTP y RTCP
Se deberá contar con la implementación de los protocolos RTP y RTCP para la transmisión de video entre pares.
Para esta instancia todavía no será necesario tener encriptación (DTLS, SRTP)
Aplicación cliente
Deberá contar con una interfaz sencilla para realizar videoconferencias de manera directa entre dos usuarios.
Además, como en esta etapa no va a ser obligatorio contar con signaling server, la idea es que puedan pedir a un usuario A que genere un SDP offer desde la interfaz, insertarlo en el usuario B para que genere un SDP answer, y luego insertarlo en el usuario A para que se pueda iniciar la transmisión de video.
Presentación
La entrega se realizará en forma de presentación, en la cual los alumnos deberán abarcar los siguientes puntos:
- Explicación general del desarrollo realizado, incluyendo diagramas de componentes y de secuencia de las funcionalidades más importantes.
- Diseño de la solución a implementar para completar el proyecto, incluyendo diagramas y su explicación.
- Recorrido por los módulos del código fuente escrito, explicando los principales contenidos.
- Demo en vivo de la aplicación gráfica, donde se pueda constatar que se pueden realizar videoconferencias entre distintas computadoras.
Todos los miembros del grupo deberán participar de la demo y explicar su participación en el proyecto, incluyendo detalles de implementación.
Fechas de entrega
Entrega intermedia: 03/11
Entrega final de la cursada: 01/12
Estas entregas serán presenciales en la sede de la Facultad.
Agregado Final 2C 2025: Soporte para audio y envio de archivos
Introducción
Mediante el uso de WebRTC no solo es posible transmitir video en tiempo real, sino que dada a su versatilidad y extensibilidad es posible adaptarlo para el envio de otros tipos de datos. Una extension natural al sistema desarrollado durante el cuatrimestre es la posibilidad de transmitir audio en tiempo real. Pero el protocolo tambien para el envio de datos en general, siendo posible enviar archivos, mensajes o incluso implementar un algoritmo de consenso sobre lo ofrecido por WebRTC.
Objetivo
Se debera incorporar al sistema desarrollado durante el cuatrimestre:
- Transmision de audio en tiempo real.
- Transmision de archivos, mediante el uso de canales de datos.
Requerimientos funcionales
Transmision de audio
Se debera implementar la transmision de audio en tiempo real, mediante el uso de WebRTC. El audio debe estar sincronizado con la transmision de video. En la interfaz grafica se debera incluir un boton para pausar la transmision de audio (mute/unmute).
Transmision de archivos
Se debera implementar la transmision de archivos, mediante el uso de data channels. En la interfaz gráfica se deberá incluir un botón para enviar archivos a la otra parte de la llamada. Siendo posible el envío de archivos de cualquier tipo y tamaño. El archivo enviado debe ser recibido por la otra parte de la llamada (siendo posible rechazar su descarga) y guardado en el disco.
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución del proyecto:
- El proyecto deberá ser desarrollado en lenguaje Rust, usando las herramientas de la biblioteca estándar.
- Se deben implementar tests unitarios y de integración de las funcionalidades que se consideren más importantes.
- El código fuente debe compilarse en la versión stable del compilador y no se permite utilizar bloques unsafe.
- La compilación no debe arrojar warnings del compilador, ni del linter clippy.
- Las funciones y los tipos de datos (struct) deben estar documentadas siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- El programa deberá funcionar en ambiente Unix / Linux.
- Solo se permite el uso crates externos ligados a la comunicación con los servicios externos (en caso de ser necesarios).
Presentación
Se deberá realizar una presentación explicando la implementación de este agregado, incluyendo las decisiones de diseño y una demostración de la funcionalidad en vivo. Dentro de los detalles de implementación se deberá explicar la solución adoptada desde el punto de vista de multi-threading, con diagramas que faciliten la explicación.
Informe final
Solo se podrán presentar a la fecha de final teniendo completo el informe final del proyecto desarrollado durante el cuatrimestre, incluyendo una sección adicional para describir la implementación de este agregado que contemple los siguientes puntos:
- Diagramas de diseño correspondientes a la implementación de este agregado que clarifiquen la estrategia de multi-threading aplicada (por ej, diagramas de secuencia)
Fechas de final
El grupo deberá presentarse en una de las fechas de examen final, tal como se publica en el calendario respectivo. Las fechas de final para el cuatrimestre actual son:
- 11/12/25
- 15/12/25
- 2/2/25
- 9/2/25
- 2/3/25
Proyecto: RustiDocs - 1C 2025
Introducción
La Universidad de Buenos Aires desea implementar un sistema de trabajo colaborativo en tiempo real que permita confeccionar documentos de texto y planillas de cálculo. El sistema será de uso no solo de toda la comunidad de la UBA sino también por usuarios de otras universidades del mundo.
Dada la carga de usuarios que se espera y su distribución geográfica variada, el sistema se debe construir con un diseño escalable que permita su correcto funcionamiento ante la alta demanda de usuarios y trafico esperado.
Luego de analizar distintas variantes de protocolos se decidió llevar adelante este desarrollo utilizando la versión distribuida de Redis (Redis Cluster) tanto para el almacenamiento de información como para el intercambio de mensajes mediante Publisher/Subscriber.
Objetivo del Proyecto
El objetivo principal del presente Trabajo Practico es desarrollar una versión en el lenguaje Rust del Cluster de Redis, respetando su protocolo cliente-servidor y desarrollando un protocolo interno de intercambio de mensajes entre nodos para implementar las principales características de replicacion y particionado, de manera de poder escalar en forma horizontal ofreciendo altos niveles de disponibilidad y tolerancia a fallos.
El objetivo secundario es desarrollar un proyecto real de software de mediana envergadura aplicando buenas prácticas de desarrollo, incluyendo entregas y revisiones periódicas.
El proyecto comienza con una investigación sobre como funciona la versión distribuida de Redis (Redis Cluster) y sus principales conceptos como Replication y Data Sharding, entre otros.
Requerimientos Funcionales
Redis Cluster
Para dar soporte a la persistencia de datos y el intercambio de mensajes entre clientes se deberá implementar un cluster de nodos de Redis cumpliendo con los siguientes requerimientos mínimos:
-
Protocolo Cliente/Servidor: El programa deberá implementar un subconjunto del protocolo Redis tal como es especificado en la documentación.
-
Comandos de Redis: Se deben implementar los comandos de Redis necesarios para poder persistir string, sets y lists. Ademas se deben soportar los comandos relacionados al intercambio de mensajes Pub/Sub.
-
Almacenamiento de datos: Los datos deberan ser almacenados en disco de manera que un nodo pueda ser reiniciado y recupere la informacion almacenada del archivo en disco.
-
Pub/Sub: el servidor debe proveer funcionalidad para soportar el paradigma de mensajería Pub/Sub, en el cual clientes que envían mensajes (publicadores) no necesitan conocer la identidad de los clientes que reciben estos mensajes. En cambio, los mensajes publicados se envían a un canal, y los clientes expresan interés en determinados mensajes subscribiéndose a uno o mas canales, y sólo reciben mensajes de estos canales, sin conocer la identidad de los publicadores. Para esto, el servidor debe mantener un registro de canales, publicadores y subscriptores. Para mas detalle, consultar la documentación de Redis.
-
Funcionamiento del Cluster: Se deben desarrollar las funcionalidades principales del Cluster de Redis como lo indica la documentación. En particular se deberá hacer foco en las siguientes caracteristicas:
- Componentes principales del cluster (main components), entre ellos la distribución de claves, la comunicación inter-nodo, su topología, entre otras.
- Implementación de la arquitectura master/replica y replica promotion.
- Tolerancia a fallos: implementar algun mecanismo de gossip para detección de fallos como se explica en la documentacion.
- Soporte a Pub/Sub en múltiples nodos como indica la documentación. A modo opcional se podrá implementar sharded Pub/Sub.
-
Configuración: el servidor deber poder ser configurado mediante un archivo de configuración, nombrado
redis.confy cuya ubicación se pasa por argumento de línea de comando:$ ./redis-server /path/to/redis.conf. -
Logs: el servidor debe mantener un registro de las acciones realizadas y los eventos ocurridos en un archivo de log. La ubicación del archivo de log estará especificada en el archivo de configuración. Como requerimiento particular del Proyecto, NO se considerará válido que el servidor mantenga un file handle global, aunque esté protegido por un lock, y que se escriba directamente al file handle.
-
Seguridad:
- Autenticación y autorización.
- Encriptación de datos en tránsito (in-transit).
- Opcional: Encriptación de datos en reposo (at-rest).
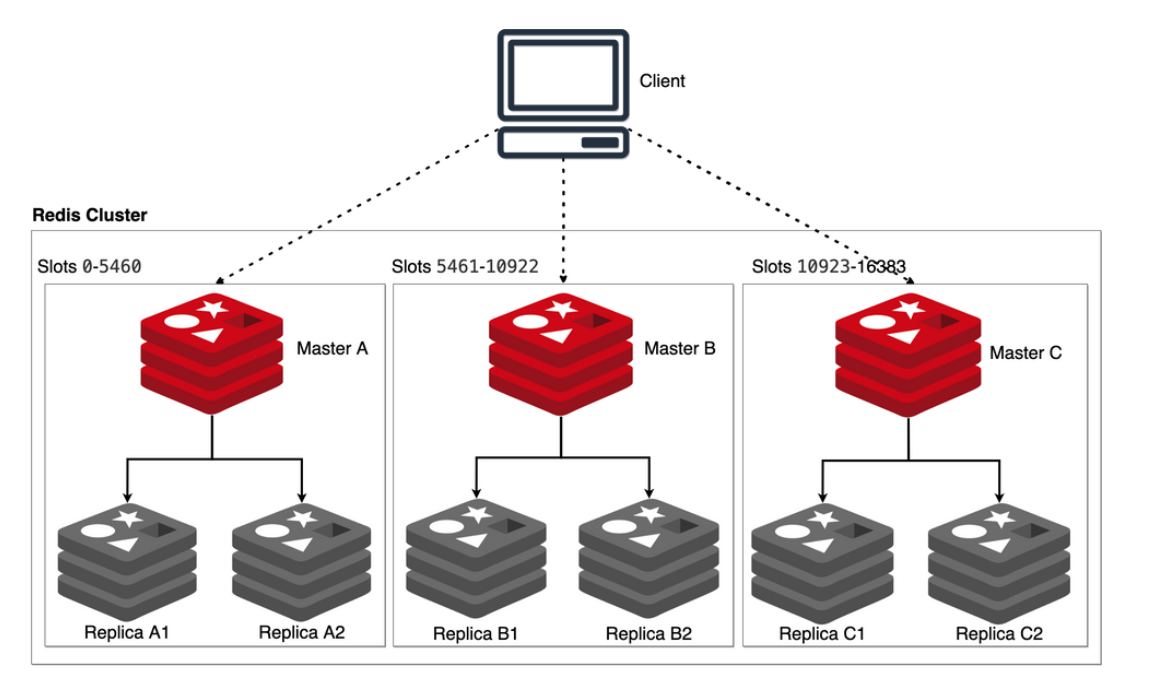
Para cumplir con los objetivos mínimos el cluster se debe configurar con al menos tres nodos master principales, cada uno de ellos con sus dos réplicas, como se observa en la imagen siguiente:
Aplicación Cliente
Se debe construir una aplicación con interfaz grafica (UI) para crear y editar documentos de manera colaborativa en tiempo real entre varios usuarios. Dicha aplicacion se conectara al servicio de Redis para obtener el listado de documentos y permitira agregar y editar documentos. Las modificaciones en un documento se deben propagar en tiempo real a todos los usuarios que se encuentran editando o visualizando el mismo documento haciendo uso del servicio de Pub/Sub provisto por el servidor de Redis implementado. Se deben soportar distintos tipos de documento, como objetivo minimo se pide implementar el documento de texto y la planilla de calculos solo con operaciones básicas. La aplicación debe tener al menos dos vistas principales, una vista con el listado de documentos existentes por tema, y la vista de edicion de un documento (sesión colaborativa).
Microservicio de Control y Persistencia
Se debe implementar un servidor liviano que se conectara al cluster de Redis como cualquier cliente pero dará servicio a los clientes respondiendo a mensajes enviados por los mismos mediante el protocolo de Pub/Sub. Por ejemplo cuando un cliente inicia una sesión para editar un documento, el mismo enviara un mensaje por el channel de dicho documento indicando que se esta uniendo a colaborar en ese documento. Este microservicio respondera al cliente enviando un mensaje de respuesta por el mismo channel incluyendo el estado actual del documento y los datos de la sesion, como por ejemplo quienes estan editando ese documento, etc. Otra de las funcionalidades de este microservicio será la de persistir frecuentemente el contenido del documento en una entrada de Redis, de manera que el mismo quede guardado.
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución del proyecto:
- El proyecto deberá ser desarrollado en lenguaje Rust, utilizando las herramientas de la biblioteca estándar.
- Se deben implementar pruebas unitarias y de integración de las funcionalidades que se consideren más importantes.
- El código fuente debe compilar en la versión estable del compilador y no se permite el uso de bloques inseguros (unsafe).
- El código deberá funcionar en ambiente Unix / Linux.
- La compilación no debe generar advertencias del compilador ni del linter clippy.
- El programa no puede contener ningún Busy-Wait, ni puede consumir recursos de CPU y/o memoria indiscriminadamente. Se debe hacer un uso adecuado tanto de la memoria como del CPU.
- Las funciones y los tipos de datos (struct) deben estar documentados siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- Las funciones no deben tener una extensión mayor a 30 líneas. Si se requiere una extensión mayor, se debe particionar en varias funciones.
- Cada tipo de dato implementado debe ser colocado en una unidad de compilación (archivo fuente) independiente.
Crates externos permitidos
Se permite el uso de los siguientes crates solo para los usos mencionados (siempre y cuando se los considere necesario):
- rand: para la generación de valores aleatorios.
- chrono: para la obtención del timestamp actual.
Nota: para la implementación de la interfaz gráfica se podrá proponer crates que deseen utilizar, los cuales serán evaluados y autorizados por el grupo docente.
Material de Consulta
Criterios de Aceptación y Corrección del Proyecto
Para el desarrollo del proyecto, se deberá observar los siguientes lineamientos generales:
- Testing: Se deberá implementar testing unitario automatizado, utilizando las herramientas de Rust de los métodos y funciones relevantes implementados. Se deberán implementar tests de integración automatizados.
- Manejo de Errores: Deberá hacerse un buen uso y administración de los casos de error, utilizando para ello, las estructuras y herramientas del lenguaje, escribiendo en forma lo más idiomática posible su tratamiento.
- Control de versiones: Se deberá utilizar la herramienta git, siguiendo las recomendaciones de la cátedra. En particular, se deberá utilizar la metodología GitHub Flow para el trabajo con ramas (branches) y la entrega continua del software.
- Trabajo en equipo: Se deberá adecuar, organizar y coordinar el trabajo al equipo, realizando tareas como revisión de código cruzada entre pares de una funcionalidad en un pull request de git.
- Merge de Branchs: Para poder hacer el merge de un branch de una funcionalidad, todos los tests pasan de forma satisfactoria
- Informe final: El trabajo debe acompañarse por un informe que debe incluir diagramas de secuencia de las operaciones más relevantes, diagrama de componentes y módulos de la arquitectura general del diseño desarrollado, todos acompañados de la explicación respectiva.
Evaluación
El desarrollo del proyecto tendrá un seguimiento directo semanal por parte del docente a cargo del grupo.
Se deberá desarrollar y presentar los avances y progreso del trabajo semana a semana (simulando un sprint de trabajo). Cada semana, cada docente realizará una valoración del estado del trabajo del grupo.
El progreso de cada semana deberá ser acorde a lo que se convenga con el docente para cada sprint. Si el mismo NO cumple con la cantidad de trabajo requerido, el grupo podrá estar desaprobado de forma prematura de la materia, a consideración del docente.
Hacia la mitad del desarrollo del proyecto se deberá entregar una versión preliminar que deberá cumplir con los requisitos mencionados en el apartado Entrega intermedia. Estos requisitos son de cumplimiento mínimo y obligatorio, aquellos grupos que lo deseen podrán implementar requisitos adicionales.
Nota importante: Se deja constancia que las funcionalidades requeridas por este enunciado son un marco de cumplimiento mínimo y que pueden haber agregados o modificaciones durante el transcurso del desarrollo por parte del docente a cargo, que formarán parte de los requerimientos a cumplir. Cabe mencionar que estos desvíos de los requerimientos iniciales se presentan en situaciones reales de trabajo con clientes.
Finalización del Proyecto
El desarrollo del proyecto finaliza el último día de clases del cuatrimestre. En esa fecha, cada grupo deberá realizar una presentación final y se hará una evaluación global del trabajo.
En dicha presentación se deberá detallar la arquitectura del proyecto, aprendizajes del mismo, y realizar una muestra funcional del desarrollo, esto es una "demo" como si fuera para el usuario final, donde se pueda observar todas las funcionalidades pedidas por el presente enunciado.
Durante la demostración en vivo, se debe poder observar tanto los requerimientos funcionales solicitados en el presente enunciado, como así también los requerimientos no funcionales, es decir, se debe poder observar y comprobar todo lo relacionado a temas como Replication, Data Sharding, Tolerancia a fallos, entre otros. Por ejemplo: se debe producir un escenario de falla de alguno de los nodos master (desconectando el nodo o cerrando la aplicación) y demostrar el mecanismo de replica promotion que permitirá a la aplicación continuar funcionando correctamente incluso al escribir datos almacenados en dicho nodo.
El trabajo debe acompañarse por un informe que debe constar de los puntos detallados a continuación: explicación general de la investigación realizada y sus conclusiones, reglas de negocio de la solución y decisiones tomadas durante el desarrollo del proyecto, diagramas de secuencia de las operaciones más relevantes, diagrama de componentes y módulos de la arquitectura general del diseño desarrollado, todos acompañados de la explicación respectiva.
Entrega Intermedia:
Los alumnos deberán realizar una entrega intermedia, la cual deberá incluir los siguientes puntos del apartado de requerimientos funcionales:
Redis Cluster
- Protocolo Cliente/Servidor
- Comandos de Redis
- Almacenamiento de datos
- Pub/Sub
- Funcionamiento del Cluster: como requerimiento obligatorio solo se pide presentar el diseño de como se va a implementar este punto en su proyecto, incluyendo diagramas que ilustren la comunicación entre nodos y los distintos escenarios importantes a soportar, por ejemplo: replica promotion, gossip, entre otros.
Aplicación Cliente
Para esta entrega intermedia se pide implementar la aplicación con interfaz grafica (UI) básica que se conecte al menos a un nodo de redis y pueda enviar y recibir mensajes. Este comportamiento se debe poder observar en una demo en vivo ya sea demostrando las funcionalidades solicitadas en la sección de requerimientos funcionales o en su defecto mediante el ingreso de comandos manualmente por parte del usuario. Además se debe presentar el diseño de como se va a ver la interfaz grafica (UI) final, describiendo las dos vistas principales que se pide implementar.
Microservicio de Control y Persistencia
Este punto es opcional para la entrega intermedia.
Presentación
La entrega se realizará en forma de Presentación en la cual los alumnos deberán abarcar los siguientes puntos:
- Explicación general del desarrollo realizado, incluyendo diagramas de componentes y de secuencia de las funcionalidades mas importantes.
- Diseño de la solución a implementar para completar el proyecto, incluyendo diagramas y su explicación.
- Recorrido por los módulos del código fuente escrito, explicando los principales contenidos.
- Demo en vivo de la aplicación gráfica y el cluster de redis, donde se pueda observar su comunicación a través del protocolo cliente/servidor e incluya las funcionalidades requeridas para la entrega intermedia.
Todos los miembros del grupo deberán participar de la demo y explicar su participación en el proyecto, incluyendo detalles de implementación.
Fechas de entrega:
Entrega intermedia: Lunes 19 de Mayo de 2025.
Entrega final de la cursada: Lunes 23 de Junio de 2025.
Estas entregas serán presenciales en la sede de la Facultad.
Agregado Final 1C 2025: Microservicio de AI
Introducción
Los Large Language Models (LLM) son modelos avanzados de inteligencia artificial, basados en arquitecturas de redes neuronales profundas, que han sido entrenados con grandes volúmenes de datos textuales. Estos modelos son capaces de comprender, generar y manipular el lenguaje natural de manera altamente contextualizada, lo que les permite desempeñarse eficientemente en tareas complejas como la redacción automática, traducción, resumen de textos y respuesta a preguntas, entre otras aplicaciones.
Objetivo
Se deberá incorporar al Trabajo Práctico realizado durante el cuatrimestre un microservicio de LLM utilizando alguno de los proveedores de infraestructura en la nube reconocidos, como por ejemplo:
- OpenAI
- Gemini API
- AWS Bedrock
- Otro (a convenir con los docentes)
Nota: Se debe seleccionar un proveedor que ofrezca una capa de uso gratuito (free tier) suficiente para probar el trabajo realizado y para realizar la demostración final en vivo.
Requerimientos funcionales
Microservicio de LLM
El microservicio de LLM será el responsable de resolver pedidos de generación o modificación de texto introducidos por el usuario mediante un prompt. Para ello se debe crear un nuevo canal (channel) de Redis mediante el cual los clientes podrán enviar solicitudes a este microservicio, las respuestas a dichas solicitudes serán enviadas por el microservicio publicando en el canal correspondiente al documento sobre el cual se hizo el pedido. De esta manera el microservicio y los clientes sólo se comunicarán a través de canales de Redis y nunca en forma directa. Para resolver los pedidos de los clientes el microservicio deberá comunicarse con el servicio externo proveedor de AI que los alumnos hayan elegido para la implementación del presente trabajo. Se pide utilizar una estrategia de multithreading que permita ejecutar varios requests en paralelo, ya sea mediante el uso de una Thread Pool o cualquier otro mecanismo implementado con channels.
Nota: Los alumnos podrán optar por utilizar un modelo local de LLM que resuelva la generación y edición de texto, en lugar de un proveedor en la nube. Se advierte en este caso que deberán investigar su funcionamiento y el modo de entrenamiento necesario para cumplir con las necesidades de este proyecto.
Interfaz gráfica
Realizar los cambios en la aplicación para permitir el uso de AI al editar un documento. Se debe poder ingresar el prompt con la solicitud deseada apuntando a cualquier parte del documento y al recibir la respuesta de la AI el resultado debe ser aplicado al punto especificado al realizar el comando. Punto extra: Se debe poder ingresar un prompt a nivel general del documento, en el cual se pida realizar cambios sobre el texto completo del documento, por ejemplo, reescribirlo mas formal, o traducirlo a otro idioma. En dicho caso el mensaje a enviar al microservicio debe contener solo el prompt y el identificador del documento y el microservicio debe ser capaz de obtener el texto completo y enviarlo al servicio externo de AI para su modificación.
Docker
Se deberán generar todos los artefactos necesarios para el deployment del cluster de Redis y los dos microservicios del trabajo practico utilizando Docker. Incluyendo la generación de imágenes, containers, recursos (por ej almacenamiento) y configuraciones necesarias para la ejecución completa del proyecto. Como mínimo se deberán incluir en la entrega los siguientes artefactos:
- Dockerfile: para la generación de la imagen del nodo.
- Docker-compose: para la definición de todos los contenedores de la red, incluyendo sus configuraciones y recursos necesarios.
- Todos los comandos necesarios para construir, iniciar, detener y destruir el cluster.
- Agregar un archivo README en la carpeta raíz del repositorio indicando todas las instrucciones para construir, iniciar, detener y destruir el ambiente, incluyendo todos los contenedores y sus datos necesarios para funcionar.
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución del proyecto:
- El proyecto deberá ser desarrollado en lenguaje Rust, usando las herramientas de la biblioteca estándar.
- Se deben implementar tests unitarios y de integración de las funcionalidades que se consideren más importantes.
- El código fuente debe compilarse en la versión stable del compilador y no se permite utilizar bloques unsafe.
- La compilación no debe arrojar warnings del compilador, ni del linter clippy.
- Las funciones y los tipos de datos (struct) deben estar documentadas siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- El programa deberá funcionar en ambiente Unix / Linux.
- Solo se permite el uso crates externos ligados a la comunicación con los servicios externos (en caso de ser necesarios).
Presentación
Se deberá realizar una presentación explicando la implementación de este agregado, incluyendo las decisiones de diseño y una demostración de la funcionalidad en vivo. Dentro de los detalles de implementación se deberá explicar la solución adoptada desde el punto de vista de multi-threading, con diagramas que faciliten la explicación. Durante la demostración en vivo del sistema se deberá poder introducir en cualquier parte de un documento un texto generado por la AI, para lo cual se debe poder ingresar el prompt con la solicitud deseada. Se debe poder demostrar como la solicitud realizada viaja al microservicio de AI y luego desde el mismo hacia el proveedor de LLM utilizado, para luego responder a esta solicitud mediante el topic correspondiente al documento sobre el que se realizó el comando.
Informe final
Solo se podrán presentar a la fecha de final teniendo completo el informe final del proyecto desarrollado durante el cuatrimestre, incluyendo una sección adicional para describir la implementación de este agregado que contemple los siguientes puntos:
- Los detalles considerados para la elección de proveedor externo de AI.
- El análisis de costos de funcionamiento del proyecto basado en una estimación de carga del sistema en funcionamiento real y utilizando la información de costos del proveedor de servicios seleccionado.
- Diagramas de diseño correspondientes a la implementación de este agregado que clarifiquen la estrategia de multi-threading aplicada (por ej, diagramas de secuencia)
Fechas de final
El grupo deberá presentarse en una de las fechas de examen final, tal como se publica en el calendario respectivo. Las fechas de final para el cuatrimestre actual son:
- lunes 7/7
- lunes 14/7
- lunes 28/7
- lunes 4/8
- lunes 11/8
Proyecto: Agentes Autónomos de Prevención
Introducción
El gobierno de la Ciudad de Buenos Aires desea implementar un sistema de vigilancia en la vía publica incorporando a sur red de monitoreo una flota de drones autónomos para realizar tareas de prevención de incidentes. Para lo cual se deberá construir una red de mensajería asincrónica, respetando alguno de los protocolos existentes de message broking como por ejemplo: MQTT, AMQP, entre otros.
Objetivo del Proyecto
El proyecto comienza con una investigación inicial respecto de los protocolos en cuestión y un análisis de ventajas y desventajas de cada uno de ellos, seguido de lo cual su equipo tomara la decisión de cual protocolo implementar. Este análisis deberá estar documentado y formara parte del informe del trabajo practico, incluyendo una introducción a los sistemas de mensajería asincrónica y ‘message brokers’ una comparativa de los protocolos relevados y la justificación de las razones para la elección del protocolo a implementar.
Una vez completada esta instancia de investigación se procederá al relevamiento de la necesidades de negocio de la aplicación a implementar, el cual no solo deberá incluir todos los puntos listados en la sección Requerimientos Funcionales de la aplicación de este presente enunciado sino también todo requerimiento que surja de su análisis y de las conversaciones y definiciones que se tomen durante el seguimiento del proyecto por parte de su equipo docente evaluador.
Servicio de mensajería
Independientemente del protocolo elegido se recomienda seguir el patrón de comunicación publisher-suscriber y la arquitectura cliente-servidor. Para lo cual se deberá implementar por un lado el servidor de mensajería y por otro lado una library que permitirá la comunicación por parte de los clientes. Se deberá tener en cuenta los siguientes requerimientos:
- Seguridad: autenticación, autorización, encriptación, etc.
- Calidad de servicio (Quality of Service, QoS): como mínimo se debe soportar 'at least one'
- Reliability: el servidor deberá tener registro de los clientes conectados y permitir a un cliente que sufra una desconexión poder reconectarse y obtener los mensajes que no recibió (sesiones y almacenamiento de mensajes)
- Configuración: debe incluir todos los parámetros necesarios para la ejecución del servidor, como el puerto, direccion IP, etc. (no esta permitido definir estos valores mediante constantes en el código)
- Logging: debe registrar un resumen de los mensajes recibidos y enviados, y cualquier error o evento significativo durante la ejecucion del servidor.
A continuacion se observa un diagrama de comunicacion entre las aplicaciones involucradas:
Requerimientos funcionales
Se deben implementar al menos 3 aplicaciones:
-
Aplicación de monitoreo: debe poder recibir la carga de incidentes por parte del usuario y notificar a la red ante la aparición de un incidente nuevo y los cambios de estado del mismo (iniciado, resuelto, etc). En la misma se podrá visualizar el estado completo del sistema incluyendo el mapa geográfico de la región con los incidentes activos y la posición y el estado de cada agente (dron) y cada cámara de vigilancia.
-
Sistema central de cámaras: el mismo tendrá la ubicación y el estado de cada cámara y permitirá agregar, quitar y modificar las mismas. El estado de cada cámara deberá ser dinámico y adaptarse a las circunstancias, es decir, cuando no haya ningún incidente cercano las cámaras permanecerán en modo de ahorro de energía, al registrarse un incidente en la zona deberán pasar a modo activo, etc.
-
Software de control del agente (dron): cada dispositivo independiente ejecutará una instancia de esta aplicación la cual se conectara a la red para recibir la información de incidentes cercanos a la zona de alcance del dron. Ademas deberá mantener la posición geográfica del dispositivo y su estado (en espera, atendiendo un incidente, etc) y en caso que corresponda la dirección y velocidad de movimiento. El dispositivo tendrá ciertos parámetros de funcionamiento, como por ejemplo la distancia máxima de alcance, duración de batería, etc. Todos estos parámetros deberán ser definidos en un archivo de configuración.
Reglas de negocio
- Los incidentes se crean ingresando su posicion geográfica a traves de la aplicación de monitoreo.
- Un incidente se resuelve cuando al menos dos agentes (drones) llegan al lugar del incidente y transcurre un tiempo definido por configuración en esa posición.
- Los agentes que reciben la notificación de un incidente deben movilizarse hacia ese incidente solo si: a. El incidente se produjo dentro del area máxima de alcance del agente (dron) b. No se reciben notificaciones de dos agentes mas cercanos que ya esten atendiendo el incidente. c. El nivel de bateria del dron se encuentra sobre los valores mínimos de operacion (definido en el archivo de configuración).
- Los agentes tienen un area de operacion asignada por configuración y deben notificar su posición y estado frecuentemente.
- Luego de atender un incidente el agente debe volver a su area de operación asignada.
- El nivel de bateria de cada agente se debera ir descargando con el paso del tiempo (se simulara su descarga).
- Cuando un agente se encuentra con niveles de bateria mínimos debe regresar a la central para su mantenimiento, es decir recuperará la bateria a niveles máximos, para luego volver a su area de operación asignada.
- Las cámaras inician su funcionamiento en modo ahorro de energia y deben pasar a estado de alerta cuando se recibe una notificación de un incidente en su area de alcance o en la de una cámara lindante (un nivel de proximidad en cada sentido de orientacion).
Interfaz gráfica
La aplicación de monitoreo debe presentar una interfaz gráfica que permita la visualizacion del estado completo del sistema incluyendo el mapa geográfico de la región con los incidentes activos y la posición y el estado de cada agente (dron) y cada cámara de vigilancia. Ademas permitira el ingreso por parte del usuario de nuevos incidentes y la modificacion manual de los mismos si hiciera falta. Opcional: La aplicacion puede permitir el envio de notificaciones a los agentes para realizar determinadas acciones como por ejemplo regresar a la central. A continuacion se muestra un ejemplo de la visualizacion del mapa geografico a modo de referencia:
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución del proyecto:
- El proyecto deberá ser desarrollado en lenguaje Rust, utilizando las herramientas de la biblioteca estándar.
- Se deben implementar pruebas unitarias y de integración de las funcionalidades que se consideren más importantes.
- El código fuente debe compilar en la versión estable del compilador y no se permite el uso de bloques inseguros (unsafe).
- El código deberá funcionar en ambiente Unix / Linux.
- La compilación no debe generar advertencias del compilador ni del linter clippy.
- Las funciones y los tipos de datos (struct) deben estar documentados siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- Las funciones no deben tener una extensión mayor a 30 líneas. Si se requiere una extensión mayor, se debe particionar en varias funciones.
- Cada tipo de dato implementado debe ser colocado en una unidad de compilación (archivo fuente) independiente.
Crates externos permitidos
Se permite el uso de los siguientes crates solo para los usos mencionados (siempre y cuando se los considere necesario):
- rand: para la generación de valores aleatorios.
- chrono: para la obtención del timestamp actual.
Nota: para la implementación de la interfaz gráfica se podrá proponer crates que deseen utilizar, los cuales serán evaluados y autorizados por el grupo docente.
Criterios de Aceptación y Corrección del Proyecto
Para el desarrollo del proyecto, se deberá observar los siguientes lineamientos generales:
- Testing: Se deberá implementar testing unitario automatizado, utilizando las herramientas de Rust de los métodos y funciones relevantes implementados. Se deberán implementar tests de integración automatizados.
- Manejo de Errores: Deberá hacerse un buen uso y administración de los casos de error, utilizando para ello, las estructuras y herramientas del lenguaje, escribiendo en forma lo más idiomática posible su tratamiento.
- Control de versiones: Se deberá utilizar la herramienta git, siguiendo las recomendaciones de la cátedra. En particular, se deberá utilizar la metodología GitHub Flow para el trabajo con ramas (branches) y la entrega continua del software.
- Trabajo en equipo: Se deberá adecuar, organizar y coordinar el trabajo al equipo, realizando tareas como revisión de código cruzada entre pares de una funcionalidad en un pull request de git.
- Merge de Branchs: Para poder hacer el merge de un branch de una funcionalidad, todos los tests pasan de forma satisfactoria
- Informe final: El trabajo debe acompañarse por un informe que debe incluir diagramas de secuencia de las operaciones más relevantes, diagrama de componentes y módulos de la arquitectura general del diseño desarrollado, todos acompañados de la explicación respectiva.
Evaluación
El desarrollo del proyecto tendrá un seguimiento directo semanal por parte del docente a cargo del grupo.
Se deberá desarrollar y presentar los avances y progreso del trabajo semana a semana (simulando un sprint de trabajo). Cada semana, cada docente realizará una valoración del estado del trabajo del grupo.
El progreso de cada semana deberá ser acorde a lo que se convenga con el docente para cada sprint. Si el mismo NO cumple con la cantidad de trabajo requerido, el grupo podrá estar desaprobado de forma prematura de la materia, a consideración del docente.
Hacia la mitad del desarrollo del proyecto se deberá entregar una versión preliminar que deberá cumplir con los requisitos mencionados en el apartado Entrega intermedia anteriormente enunciado. Estos requisitos son de cumplimiento mínimo y obligatorio, aquellos grupos que lo deseen podrán implementar requisitos adicionales.
Nota importante: Se deja constancia que las funcionalidades requeridas por este enunciado son un marco de cumplimiento mínimo y que pueden haber agregados o modificaciones durante el transcurso del desarrollo por parte del docente a cargo, que formarán parte de los requerimientos a cumplir. Cabe mencionar que estos desvíos de los requerimientos iniciales se presentan en situaciones reales de trabajo con clientes.
Finalización del Proyecto
El desarrollo del proyecto finaliza el último día de clases del cuatrimestre. En esa fecha, cada grupo deberá realizar una presentación final y se hará una evaluación global del trabajo.
En dicha presentación se deberá detallar la arquitectura del proyecto, aprendizajes del mismo, y realizar una muestra funcional del desarrollo, esto es una "demo" como si fuera para el usuario final.
El trabajo debe acompañarse por un informe que debe constar de los puntos detallados a continuación: explicación general de la investigación realizada y sus conclusiones, reglas de negocio de la solución y decisiones tomadas durante el desarrollo del proyecto, diagramas de secuencia de las operaciones más relevantes, diagrama de componentes y módulos de la arquitectura general del diseño desarrollado, todos acompañados de la explicación respectiva.
Entrega Intermedia
Los alumnos deberán realizar una entrega intermedia, la cual deberá incluir el desarrollo del Servicio de Mensajería con la implementación del protocolo completo y su comunicación con la Aplicación de monitoreo y el Sistema central de cámaras, ambos detallados en la sección de Requerimientos funcionales.
Nota: El desarrollo de la interfaz gráfica podrá estar incompleto pero se deberá presentar al menos un prototipo de cómo será la misma y cómo se implementará (tecnologías, pantallas, usabilidad, etc.)
La entrega se realizará en forma de Presentación en la cual los alumnos deberán abarcar los siguientes puntos:
- Explicación general de la investigación realizada y sus conclusiones.
- Diseño de la solución a implementar, incluyendo diagramas.
- Recorrido por los módulos del código fuente escrito, explicando los principales contenidos.
- Demo en vivo de las aplicaciones incluidas para esta entrega, donde se pueda observar su comunicación con el servicio de mensajería y la correcta entrega y recepción de mensajes.
Todos los miembros del grupo deberán participar de la demo y explicar su participación en el proyecto, incluyendo detalles de implementación.
Fechas de entrega:
Entrega intermedia: 27 de Mayo de 2024.
Entrega final de la cursada: 24 de Junio de 2024.
Estas entregas serán presenciales en la sede de la Facultad.
Agregado Final 1C 2024: Reconocimiento de Imágenes
Introducción
El reconocimiento de imágenes es una tecnología de inteligencia artificial que permite a las computadoras interpretar y comprender el contenido de imágenes digitales. Utiliza algoritmos de aprendizaje automático, particularmente redes neuronales convolucionales (CNN), para identificar y clasificar objetos, personas, escenas y otras características visuales dentro de una imagen. Este proceso comienza con la adquisición y preprocesamiento de grandes volúmenes de imágenes etiquetadas, seguido del entrenamiento del modelo que aprende a reconocer patrones y características específicas. Una vez entrenado, el modelo se evalúa y se implementa en aplicaciones prácticas, como seguridad y vigilancia, diagnóstico médico, vehículos autónomos y comercio electrónico.
Objetivo
Se deberá incorporar la tecnología de reconocimiento de imágenes al sistema central de cámaras desarrollado durante el Trabajo Práctico del cuatrimestre, utilizando alguno de los proveedores de infraestructura en la nube reconocidos, como por ejemplo:
- Azure AI Vision
- Google Vision AI
- Amazon Rekognition Image
- Otra, a convenir con los docentes
Nota: Se debe seleccionar un proveedor que ofrezca una capa de uso gratuito (free tier) suficiente para probar el trabajo realizado y para realizar la demostración final en vivo con una carga de procesamiento mediana, como mínimo de 10 requests por minuto. No se permite el uso de OpenAI Vision debido a que no cumple con esta caracteristica.
Requerimientos funcionales
El sistema central de cámaras deberá ser capaz de procesar imágenes generadas por las cámaras que se encuentren en modo pasivo, y utilizar la tecnología de reconocimiento de imágenes para detectar potenciales incidentes. En caso de considerar que la imagen procesada corresponde a un incidente deberá hacer uso del sistema de mensajería para publicar un mensaje que describa esta situación, y por consiguiente la aplicación deberá automáticamente generar el incidente correspondiente y poner en marcha todo el circuito de resolución de incidentes implementado durante el desarrollo del Trabajo Práctico.
Para simular la generación de imágenes por parte de la cámaras se deberá especificar un directorio por configuración en el cual se irán copiando manualmente las imágenes y las mismas deberán ser procesadas por la aplicación inmediatamente, es decir la aplicacion deberá monitorear frecuentemente estos directorios para detectar la presencia de nuevas imágenes para procesar. Este directorio deberá contener subdirectorios por cada una de las cámaras en funcionamiento de manera que la imagen depositada en un directorio correspondiente a una cámara particular se considerará como una imagen tomada por dicha cámara.
Para comunicarse con el proveedor de servicios de la nube se debe utilizar una estrategia de multithreading que permita ejecutar varios requests en paralelo, ya sea mediante el uso de una Thread Pool o cualquier otro mecanismo implementado con channels.
Nota: Los alumnos podrán optar por utilizar un modelo local de AI que resuelva el procesamiento de imágenes, en lugar de un proveedor en la nube. Se advierte en este caso que deberán investigar su funcionamiento y el modo de entrenamiento necesario para cumplir con las necesidades de este proyecto.
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución del proyecto:
- El proyecto deberá ser desarrollado en lenguaje Rust, usando las herramientas de la biblioteca estándar.
- Se deben implementar tests unitarios y de integración de las funcionalidades que se consideren más importantes.
- El código fuente debe compilarse en la versión stable del compilador y no se permite utilizar bloques unsafe.
- La compilación no debe arrojar warnings del compilador, ni del linter clippy.
- Las funciones y los tipos de datos (struct) deben estar documentadas siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- El programa deberá funcionar en ambiente Unix / Linux.
- Solo se permite el uso crates externos ligados a la comunicación con los servicios externos (en caso de ser necesarios).
Presentación
Se deberá realizar una presentación explicando la implementación de este agregado, incluyendo las decisiones de diseño y una demostración de la funcionalidad en vivo. Dentro de los detalles de implementación se deberá explicar la solución adoptada desde el punto de vista de multi-threading, con diagramas que faciliten la explicación. Durante la demostración en vivo del sistema se deberá ir copiando distintas imagenes (una a una) a los directorios correspondientes de varias cámaras y a medida que estas imágenes se van copiando y procesando por la aplicacion, se deberá visualizar como las imágenes que den cuenta de potenciales incidentes generan los correspondientes incidentes en el sistema (en tiempo real) y su eventual atención y resolución por parte de los agentes.
Informe final
Solo se podrán presentar a la fecha de final teniendo completo el informe final del proyecto desarrollado durante el cuatrimestre, incluyendo una sección adicional para describir la implementación de este agregado que contemple los siguientes puntos:
- Los detalles considerados para la elección de proveedor externo de AI.
- El análisis de costos de funcionamiento del proyecto basado en una estimación de carga del sistema en funcionamiento real y utilizando la información de costos del proveedor de servicios seleccionado.
- Diagramas de diseño correspondientes a la implementación de este agregado que clarifiquen la estrategia de multi-threading aplicada (por ej, diagramas de secuencia)
Fechas de final
El grupo deberá presentarse en una de las fechas de examen final, tal como se publica en el calendario respectivo.
Las fechas de final para el cuatrimestre actual son:
- lunes 1/7
- lunes 15/7
- lunes 29/7
- lunes 5/8
- lunes 12/8
Proyecto: Aerolíneas Rusticas - 2C 2024
Introducción
Aerolíneas Rusticas les solicita implementar un sistema de control de vuelos global, debido a que necesita controlar los vuelos tanto nacionales, como internacionales, teniendo base en varios países. Para lograr este objetivo se desea implementar una base de datos distribuida que sea escalable y posea tolerancia a fallos.
Objetivo del Proyecto
El objetivo principal de este proyecto es la implementación de un sistema de gestión de datos de vuelos de aeropuertos utilizando una base de datos distribuida compatible con Cassandra. Se deberá diseñar e implementar una base de datos distribuida que permita el almacenamiento y recuperación eficiente de datos distribuidos en múltiples nodos y soporte tolerancia a fallos ante la caída de uno o mas nodos de la red.
El objetivo secundario es desarrollar un proyecto real de software de mediana envergadura aplicando buenas prácticas de desarrollo, incluyendo entregas y revisiones periódicas.
El proyecto comienza con una investigación sobre como funcionan las bases de datos distribuidas, en particular el motor de base de datos Cassandra. Incluyendo conceptos como Consistent Hashing, Replication Factor, Consistency Level, Read Repair, entre otros, así como también el diseño y modelado de bases de datos distribuidas.
Requerimientos Funcionales
Aplicación de Vuelos
Se debe construir una aplicación con interfaz grafica (UI) que despliegue un mapa geográfico mundial y permita mostrar datos de vuelos (arribos y partidas) seleccionando un aeropuerto del mapa. Dentro de los datos a visualizar existen dos grupos de información bastante diferenciados: por un lado la información del Estado de los vuelos, la cual deberá tener un nivel de consistencia fuerte (strong consistency) y por otro lado los datos de Seguimiento de vuelos en curso, que incluyen valores de tracking de los vuelos en tiempo real, como la velocidad, ubicación actual (latitud y longitud), nivel de combustible, entre otros, para estos valores se utilizara un nivel de consistencia débil (weak consistency). Se deberá tener en cuenta los patrones de acceso a esta información por fecha y aeropuerto de origen o destino de manera de poder crear las particiones adecuadas para estos tipos de acceso (origen y fecha / destino y fecha). Dicha interfaz deberá permitir editar el Estado de los vuelos (strong consistency), ya sea para agregar nuevos vuelos o modificar vuelos existentes, por ejemplo para modificar un vuelo on-time a delayed.
Servidor de Base de Datos
Para dar soporte a esta aplicación se debe construir un motor de base de datos distribuidas Cassandra-compatible, es decir que soporte tanto el lenguaje de consultas CQL (Cassandra Query Language), como también el protocolo de comunicación nativo de Cassandra. El cluster a utilizar deberá contener entre 5 y 8 nodos y estos nodos se comunicaran entre si utilizando el protocolo Gossip para mantener la informacion de estado de cada nodo. Se deberán tener en cuenta conceptos como Consistent Hashing, Replication Factor, Consistency Level, Read-Repair, etc.
Dentro de las funcionalidades del motor de base de datos se deberán contemplar los siguientes puntos:
-
Modelado de Datos:
- Diseño del esquema de la base de datos, incluyendo keyspaces y tablas.
- Definición de particiones y clustering de columnas para optimizar el rendimiento.
-
Operaciones CRUD:
- Operaciones de creación, lectura, actualización y eliminación utilizando CQL (Cassandra Query Language).
- Implementación de Read-Repair
-
Replicación y Consistencia:
- Configuración de estrategias de replicación (Replication Factor).
- Soporte a distintos niveles de consistencia (Consistency Level).
-
Funcionamiento de Clúster:
- Soporte al protocolo de comunicacion nativo de Cassandra.
- Implementación del protocolo Gossip para comunicación entre nodos.
- Tolerancia a fallo de uno o mas nodos del cluster.
- Punto Bonus (opcional): Implementación de Hinted Handoff para recuperación de datos ante la desconexión de un nodo.
- Punto Bonus (opcional): demostrar la compatibilidad utilizando un cliente comercial de Cassandra.
-
Seguridad:
- Autenticación y autorización.
- Encriptación de datos en tránsito (in-transit).
- Opcional: Encriptación de datos en reposo (at-rest).
Simulador de Vuelos
Se deberá desarrollar una aplicación de consola encargada de simular el comportamiento de los vuelos. Dicha aplicación permitirá introducir un vuelo, indicando el número de vuelo, origen, destino y velocidad estimada promedio y simulará el comportamiento de ese vuelo generando datos de tracking del vuelo, como la posición en latitud y longitud, altitud, nivel de combustible, velocidad actual, entre otros, esta información se guardara como datos de Seguimiento de vuelos en curso (weak consistency). Esta aplicación deberá contemplar alguna estrategia de multithreading para soportar la simulación de múltiples vuelos al mismo tiempo, como por ejemplo mediante el uso de ThreadPool.
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución del proyecto:
- El proyecto deberá ser desarrollado en lenguaje Rust, utilizando las herramientas de la biblioteca estándar.
- Se deben implementar pruebas unitarias y de integración de las funcionalidades que se consideren más importantes.
- El código fuente debe compilar en la versión estable del compilador y no se permite el uso de bloques inseguros (unsafe).
- El código deberá funcionar en ambiente Unix / Linux.
- La compilación no debe generar advertencias del compilador ni del linter clippy.
- El programa no puede contener ningún Busy-Wait, ni puede consumir recursos de CPU y/o memoria indiscriminadamente. Se debe hacer un uso adecuado tanto de la memoria como del CPU.
- Las funciones y los tipos de datos (struct) deben estar documentados siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- Las funciones no deben tener una extensión mayor a 30 líneas. Si se requiere una extensión mayor, se debe particionar en varias funciones.
- Cada tipo de dato implementado debe ser colocado en una unidad de compilación (archivo fuente) independiente.
Crates externos permitidos
Se permite el uso de los siguientes crates solo para los usos mencionados (siempre y cuando se los considere necesario):
- rand: para la generación de valores aleatorios.
- chrono: para la obtención del timestamp actual.
Nota: para la implementación de la interfaz gráfica se podrá proponer crates que deseen utilizar, los cuales serán evaluados y autorizados por el grupo docente.
Material de Consulta
- Documentación de Apache Cassandra
- Cassandra Query Language (CQL)
- Gossip Protocol
- Cassandra Architecture
- Curso: Foundations of Apache Cassandra
Criterios de Aceptación y Corrección del Proyecto
Para el desarrollo del proyecto, se deberá observar los siguientes lineamientos generales:
- Testing: Se deberá implementar testing unitario automatizado, utilizando las herramientas de Rust de los métodos y funciones relevantes implementados. Se deberán implementar tests de integración automatizados.
- Manejo de Errores: Deberá hacerse un buen uso y administración de los casos de error, utilizando para ello, las estructuras y herramientas del lenguaje, escribiendo en forma lo más idiomática posible su tratamiento.
- Control de versiones: Se deberá utilizar la herramienta git, siguiendo las recomendaciones de la cátedra. En particular, se deberá utilizar la metodología GitHub Flow para el trabajo con ramas (branches) y la entrega continua del software.
- Trabajo en equipo: Se deberá adecuar, organizar y coordinar el trabajo al equipo, realizando tareas como revisión de código cruzada entre pares de una funcionalidad en un pull request de git.
- Merge de Branchs: Para poder hacer el merge de un branch de una funcionalidad, todos los tests pasan de forma satisfactoria
- Informe final: El trabajo debe acompañarse por un informe que debe incluir diagramas de secuencia de las operaciones más relevantes, diagrama de componentes y módulos de la arquitectura general del diseño desarrollado, todos acompañados de la explicación respectiva.
Evaluación
El desarrollo del proyecto tendrá un seguimiento directo semanal por parte del docente a cargo del grupo.
Se deberá desarrollar y presentar los avances y progreso del trabajo semana a semana (simulando un sprint de trabajo). Cada semana, cada docente realizará una valoración del estado del trabajo del grupo.
El progreso de cada semana deberá ser acorde a lo que se convenga con el docente para cada sprint. Si el mismo NO cumple con la cantidad de trabajo requerido, el grupo podrá estar desaprobado de forma prematura de la materia, a consideración del docente.
Hacia la mitad del desarrollo del proyecto se deberá entregar una versión preliminar que deberá cumplir con los requisitos mencionados en el apartado Entrega intermedia. Estos requisitos son de cumplimiento mínimo y obligatorio, aquellos grupos que lo deseen podrán implementar requisitos adicionales.
Nota importante: Se deja constancia que las funcionalidades requeridas por este enunciado son un marco de cumplimiento mínimo y que pueden haber agregados o modificaciones durante el transcurso del desarrollo por parte del docente a cargo, que formarán parte de los requerimientos a cumplir. Cabe mencionar que estos desvíos de los requerimientos iniciales se presentan en situaciones reales de trabajo con clientes.
Finalización del Proyecto
El desarrollo del proyecto finaliza el último día de clases del cuatrimestre. En esa fecha, cada grupo deberá realizar una presentación final y se hará una evaluación global del trabajo.
En dicha presentación se deberá detallar la arquitectura del proyecto, aprendizajes del mismo, y realizar una muestra funcional del desarrollo, esto es una "demo" como si fuera para el usuario final, donde se pueda observar todas las funcionalidades pedidas por el presente enunciado.
Durante la demostración en vivo, se debe poder observar tanto los requerimientos funcionales solicitados en el presente enunciado, como así también los requerimientos no funcionales, es decir, se debe poder observar y comprobar todo lo relacionado a temas como Replication Factor, Consistency Level, Read-Repair, Tolerancia a fallos, entre otros. Por ejemplo: se debe producir un escenario de falla de alguno de los nodos (desconectando el nodo o cerrando la aplicación) y demostrar que la aplicación continua funcionando correctamente incluso al solicitar datos almacenados en dicho nodo.
El trabajo debe acompañarse por un informe que debe constar de los puntos detallados a continuación: explicación general de la investigación realizada y sus conclusiones, reglas de negocio de la solución y decisiones tomadas durante el desarrollo del proyecto, diagramas de secuencia de las operaciones más relevantes, diagrama de componentes y módulos de la arquitectura general del diseño desarrollado, todos acompañados de la explicación respectiva.
Entrega Intermedia:
Los alumnos deberán realizar una entrega intermedia, la cual deberá incluir los siguientes puntos:
- Modelado y Diseño de Datos:
- Creación de keyspaces y tablas.
- Definición de particiones y clustering keys.
- Operaciones Básicas:
- Inserción de datos en las tablas.
- Consultas básicas de datos.
- Actualización y eliminación de registros (opcional).
- Replicación Básica:
- Estrategias de replicación simple.
- Replicacion de datos en mas de un nodo según el valor de Replication Factor.
- Documentación:
- Documentación del diseño del esquema de tablas y las decisiones de particionamiento.
- Diagramas de explicación de la solución implementada.
- Interfaz grafica:
- Interfaz grafica que muestre el mapa geográfico destacando los aeropuertos.
- Seleccionando un aeropuerto y una fecha se deberá poder ver los vuelos entrantes y salientes.
La entrega se realizará en forma de Presentación en la cual los alumnos deberán abarcar los siguientes puntos:
- Explicación general de la investigación realizada y sus conclusiones.
- Diseño de la solución a implementar, incluyendo diagramas.
- Recorrido por los módulos del código fuente escrito, explicando los principales contenidos.
- Demo en vivo de la aplicación gráfica y el cluster de base de datos, donde se pueda observar su comunicación a través del protocolo nativo de Cassandra e incluya las funcionalidades requeridas para la entrega intermedia.
Todos los miembros del grupo deberán participar de la demo y explicar su participación en el proyecto, incluyendo detalles de implementación.
Fechas de entrega:
Entrega intermedia: Lunes 28 de Octubre de 2024. Entrega final de la cursada: Lunes 2 de Diciembre de 2024. Estas entregas serán presenciales en la sede de la Facultad.
Agregado Final 2C 2024: Containerization
Introducción
Containerization es un enfoque de virtualización que permite ejecutar aplicaciones en entornos aislados llamados contenedores. A diferencia de las máquinas virtuales tradicionales, que requieren un sistema operativo completo para cada instancia, los contenedores comparten el mismo núcleo del sistema operativo, lo que los hace más ligeros y eficientes en términos de recursos.
Docker
Docker es una plataforma de software que permite crear, implementar y ejecutar aplicaciones en contenedores, empaquetando el código de la aplicación junto con todas sus dependencias, bibliotecas y configuraciones necesarias para que funcione correctamente.
Objetivo
El objetivo consiste en implementar el servidor distribuido desarrollado durante el cuatrimestre en una serie de contenedores de Docker, utilizando un contenedor para cada nodo del cluster de base de datos. Además se incorporaran algunos requerimientos para hacer mas flexible la distribución de nodos (instancias) del cluster y el logging de intercambio de mensajes entre nodos.
Requerimientos funcionales
Docker
Se deberán generar todos los artefactos necesarios para el deployment del cluster de nodos utilizando Docker. Incluyendo la generación de imágenes, containers, recursos (por ej almacenamiento) y configuraciones necesarias para la ejecución del servidor de base de datos distribuido. Como mínimo se deberán incluir en la entrega los siguientes artefactos:
- Dockerfile: para la generación de la imágen del nodo.
- Docker-compose: para la definición de todos los contenedores de la red, incluyendo sus configuraciones y recursos necesarios.
- Todos los comandos necesarios para construir, iniciar, detener y destruir el cluster.
- Agregar un archivo README en la carpeta raíz del repositorio indicando todas las instrucciones para construir, iniciar, detener y destruir el ambiente, incluyendo todos los nodos y sus datos necesarios para funcionar.
Reconfiguración dinámica del cluster
Se pide realizar todos los cambios necesarios para que el sistema distribuido de DB soporte la incorporación y/o desvinculación de un nodo de la red. Es decir, dado un cluster de N nodos se deberá poder iniciar e incorporar un nuevo nodo a la red, de manera que este mismo reciba un rango de particionamiento para cada una de las tablas de la DB y los nodos existentes le envíen la información correspondiente a los datos del segmento de partición asignado al nuevo nodo. El nuevo nodo deberá entonces recibir la información de tablas, particiones y datos almacenados (de su propio segmento de particiones unicamente)
Logger
De manera de poder visualizar facilmente el funcionamiento de los nodos en Docker se pide implementar un Logger que registre todos los mensajes enviados y recibidos por el nodo. Dicho logger deberá poder escribir en un archivo y en la salida estándar (stdout) al mismo tiempo, de manera de poder visualizar el log utilizando el comando: docker logs.
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución del proyecto:
- El proyecto deberá ser desarrollado en lenguaje Rust, utilizando las herramientas de la biblioteca estándar.
- Se deben implementar pruebas unitarias y de integración de las funcionalidades que se consideren más importantes.
- El código fuente debe compilar en la versión estable del compilador y no se permite el uso de bloques inseguros (unsafe).
- El código deberá funcionar en ambiente Unix / Linux.
- La compilación no debe generar advertencias del compilador ni del linter clippy.
- El programa no puede contener ningún Busy-Wait, ni puede consumir recursos de CPU y/o memoria indiscriminadamente. Se debe hacer un uso adecuado tanto de la memoria como del CPU.
- Las funciones y los tipos de datos (struct) deben estar documentados siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- Las funciones no deben tener una extensión mayor a 30 líneas. Si se requiere una extensión mayor, se debe particionar en varias funciones.
- Cada tipo de dato implementado debe ser colocado en una unidad de compilación (archivo fuente) independiente.
Presentación
Se deberá realizar una presentación explicando la implementación de esta nueva consigna, incluyendo las decisiones de diseño y una demostración de la funcionalidad en vivo. Dentro de los detalles de implementación se deberá explicar la solución adoptada desde el punto de vista de multi-threading, con diagramas que faciliten la explicación. Durante la demostración en vivo, se debe poder observar tanto los requerimientos funcionales solicitados en el presente enunciado, como así también los requerimientos no funcionales, es decir, se debe demostrar como se agrega un nuevo nodo a la red y el mismo recibe toda la información necesaria para funcionar, así como también el funcionamiento de la base de datos antes y después de agregar el nuevo nodo, utilizando las aplicaciones implementadas durante el cuatrimestre (visualización de vuelos y simulación de vuelos en curso) De la misma manera se deberá demostrar como se construyen todos los contenedores utilizando Docker y como se inicia, se agrega un nodo a la red, se quita un nodo de la red, se detienen los contenedores; utilizando y explicando los correspondientes comandos de Docker empleados.
Informe final
Solo se podrán presentar a la fecha de final teniendo completo el informe final del proyecto desarrollado durante el cuatrimestre, incluyendo una sección adicional para describir la implementación de esta consigna con sus diagramas de diseño (por ej, diagramas de secuencia) y documentación relacionada.
Fechas de final
El grupo deberá presentarse en una de las fechas de examen final, tal como se publica en el calendario respectivo. Las fechas de final para el cuatrimestre actual son:
- lunes 9/12/2024
- lunes 16/12/2024
- lunes 3/2/2025
- lunes 10/2/2025
- lunes 24/2/2025
Proyecto: Bitcoin - 1er Cuatrimestre 2023
Fechas de entrega:
- Entrega intermedia: lunes 22 de mayo
- Entrega final de la cursada: lunes 26 de junio
Estas entregas serán presenciales en la sede de la Facultad.
Alcance de la entrega intermedia:
La entrega intermedia deberá incluir los siguientes puntos desarrollados en la seccion Requerimientos funcionales:
- Conexion a la red
- Comportamiento del Nodo
Opcional: Se deberá presentar una interfaz gráfica, similar a la imagen que se observa en Ver transacciones pero utilizando distintas pestañas para Headers, Bloques y Transacciones
La entrega se realizara en forma de Demostración (Demo) en la cual los alumnos deberán abarcar los siguientes puntos:
- Explicación general de la solución, incluyendo diagramas que muestren el diseño desarrollado.
- Recorrido por el código fuente escrito, explicando los principales contenidos de cada módulo.
- Demo en vivo del programa, en donde se comprobará que el programa cumple con los puntos solicitados.
Nota: Todos los miembros del grupo deberán participar de la demo y explicar su participación en el proyecto, incluyendo detalles de implementación.
Introduccion a Blockchain
Blockchain es una tecnología descentralizada que se utiliza para registrar transacciones de manera segura e inmutable. La información se organiza en bloques conectados en una cadena y cada participante en la red tiene una copia idéntica del registro completo. La seguridad proviene de la criptografía y la naturaleza descentralizada del sistema. Se utiliza comúnmente para la gestión de criptomonedas, pero también tiene aplicaciones en otras áreas como la gestión de cadenas de suministro y la votación electrónica.
Introduccion a Bitcoin
Bitcoin es una criptomoneda digital descentralizada basada en una red de nodos que ejecutan software Bitcoin Core. La red está asegurada mediante el uso de criptografía y un sistema de incentivos llamado "minería de Bitcoin", donde los participantes compiten para resolver un problema matemático complejo y validar transacciones en la red. Las transacciones se registran en una base de datos blockchain, que contiene un registro inmutable de todas las transacciones de Bitcoin desde su creación. El White Paper original fue escrito en 2009 por una persona o grupo anónimo de personas bajo el seudónimo de Satoshi Nakamoto.
Importante: durante el desarrollo del proyecto utilizaremos la red de testing de Bitcoin: 'testnet' la cual no involucra dinero real y permite obtener test coins para realizar pruebas.
Objetivo del Proyecto
El objetivo principal del presente proyecto de desarrollo consiste en la implementacion de un Nodo Bitcoin con funcionalidades acotadas que se detallan en el presente enunciado. Siguiendo las guias de desarrollo y especificaciones de Bitcoin.
El objetivo secundario del proyecto consiste en el desarrollo de un proyecto real de software de mediana envergadura aplicando buenas prácticas de desarrollo de software, incluyendo entregas y revisiones usando un sistema de control de versiones.
Se espera que se haga un uso lo más idiomático posible del lenguaje de programación Rust, siguiendo los estándares que éste promueve.
Requerimientos funcionales
Los siguientes son los requerimientos funcionales para el desarrollo del Trabajo.
El nodo de Bitcoin deberá ser capaz de descargar y almacenar la cadena completa de headers desde el inicio de la blockchain y los bloques completos a partir de una fecha determinada, que correspondera al inicio del presente proyecto.
A su vez debera mantener actualizada la informacion de nuevos bloques (incluyendo sus headers y las transacciones incluidas) y nuevas transacciones (no confirmadas) que se van trasmitiendo por la red.
Tambien debera mantener la lista de UTXO (unspent transactions) a partir de la fecha mencionada y permitir al usuario realizar transacciones utilizando dichas UTXO.
Protocolo
El protocolo de red de Bitcoin permite mantener una red peer to peer (P2P) entre nodos, con el objetivo de intercambiar informacion sobre bloques y transacciones.

Conexion a la red
Los pasos para conectarse a la red estan explicados en la guia de desarrollo P2P network. Durante todo el desarrollo del proyecto utilizaremos la red de pruebas de Bitcoin: 'testnet'. Se debera tener en cuenta las siguientes consideraciones:
- Peer Discovery: utilizar alguna de las siguientes direcciones de DNS:
- seed.testnet.bitcoin.sprovoost.nl -recomendado-
- testnet-seed.bitcoin.jonasschnelli.ch
- seed.tbtc.petertodd.org
- testnet-seed.bluematt.me
- Handshake: se debera conectar con la mayor cantidad de nodos posible, obtenidos de la resolucion de los DNS arriba mencionados. Se decidira que valor de Protocol Version utilizar, el cual estara definido por configuracion.
- Initial Block Download: se sugiere implementar la descarga utilizando la modalidad Headers first teniendo en cuenta que se debe descargar la totalidad de los headers pero solo la informacion de bloques a partir de la fecha de inicio del proyecto, la cual debera estar definida por configuracion. Se recomienda el uso de multiples threads para paralelizar la descarga de Bloques.
- Block Broadcasting: se puede optar por recibir 'Direct Headers Announcement' para lo cual se debera especificar dicha modalidad durante el Handshake mediante el mensaje sendheaders
- Alerts: estan discontinuadas y en caso de recibir una de ellas podemos ignorar el mensaje.
Nota: los parametros anteriormente definidos no pueden ser hardcodeados y deberan leerse del archivo de configuracion y/o variables de ambiente.
Comportamiento del Nodo
- Block Validations: ante la llegada de nuevos bloques se debera validar la Proof Of Work de cada bloque recibido y la Proof of Inclusion de las transacciones del bloque, generando el Merkle Tree con las transacciones del bloque y comparando el Merkle Root generado con el especificado en el header del Bloque.
- UTXO set: en todo momento se debera mantener la lista de 'unspent transactions' de manera de poder utilizar la misma para realizar transacciones (ver siguiente punto).
- El nodo, dada una transaccion y un bloque, debe poder devolver una merkle proof of inclusion, para que el usuario pueda verificar la existencia de la transaccion en el bloque.
Funciones de Wallet
Nota: como prerequisito para poder probar estas operaciones se debera crear una cuenta en Testnet y obtener test coins de prueba. Link para crear una cuenta y obtener coins
A continuacion se obsevan las funcionalidades provistas por una Wallet y cuales de las mismas estaran dentro del alcance del proyecto.
 La zona verde corresponde a las funcionalidades incluidas en el alcance del proyecto.
La zona verde corresponde a las funcionalidades incluidas en el alcance del proyecto.
Detalle de las funcionalidades:
- El usuario podra ingresar una o mas cuentas que controla, especificando la clave publica y privada de cada una.
- Para cada cuenta se debera visualizar el balance de la misma, es decir la suma de todas sus UTXO disponibles al momento.
- Cada vez que se recibe una Transaccion en la red que involucra una de las cuentas del usuario se debera informar al usuario, aclarando que la misma aun no se encuentra incluida en un Bloque.
- Cada vez que se recibe un nuevo Bloque generado se debera verificar si alguna de las transacciones del punto anterior se encuentra en dicho bloque y se informara al usuario.
- En todo momento el usuario podra realizar una Transaccion, ingresando la informacion necesaria para la misma. Como minimo se debera soportar P2PKH. La transaccion generada se debera comunicar al resto de los nodos de la red.
- Adicionalmente, el usuario podra pedir una prueba de inclusión de una transacción en un bloque, y verificarla localmente
Importante: luego de realizada una transaccion podremos verificar que la misma se genero correctamente mediante el uso de un blockchain explorer de testnet, por ejemplo bitaps
Archivo de Configuracion
El nodo deber poder ser configurado mediante un archivo de configuración, nombrado nodo.conf y cuya ubicación se pasara por argumento de línea de comando: $ ./nodo-rustico /path/to/nodo.conf.
Todos los valores de configuracion mencionados en este enunciado y cualquier otro parametro necesario para la ejecucion del programa debera estar definido en este archivo.
No se permite definir valores hardcodeados en el codigo fuente, ya sean direcciones IP, puertos o cualquier otra informacion necesaria.
Archivo de Log
El nodo debe mantener un registro de los mensajes recibidos en un archivo de log. La ubicación del archivo de log estará especificada en el archivo de configuración.
Como requerimiento particular del Proyecto, NO se considerará válido que el servidor mantenga un file handle global, aunque esté protegido por un lock, y que se escriba directamente al file handle. La arquitectura deberá contemplar otra solución.
Interfaz gráfica
Se debe implementar una interfaz gráfica utilizando la biblioteca GTK, mediante el crate gtk-rs. Se recomienda utilizar Glade y GTK3.
La interfaz deberá permitir el uso completo de las funcionalidades solicitadas y su apariencia deberá ser similar a la de bitcoin-qt.
Vista general

Crear transacciones

Ver transacciones

Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución del proyecto:
- El proyecto deberá ser desarrollado en lenguaje Rust, usando las herramientas de la biblioteca estándar.
- Se deben implementar tests unitarios y de integración de las funcionalidades que se consideren más importantes.
- No se permite utilizar crates externos más allá de los mencionados en dicha sección.
- El código fuente debe compilarse en la versión stable del compilador y no se permite utilizar bloques unsafe.
- El código deberá funcionar en ambiente Unix / Linux.
- La compilación no debe arrojar warnings del compilador, ni del linter clippy.
- Las funciones y los tipos de datos (struct) deben estar documentadas siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- Las funciones no deben tener una extensión mayor a 30 líneas. Si se requiriera una extensión mayor, se deberá particionarla en varias funciones.
- Cada tipo de dato implementado debe ser colocado en una unidad de compilación (archivo fuente) independiente.
Crates externos permitidos
Se permite el uso de los siguientes crates sólo para los usos mencionados (siempre y cuando se los considere necesario):
- rand: para la generación de valores aleatorios.
- chrono: para la obtención del timestamp actual.
- bitcoin_hashes: para utilizar funciones de hash como SHA256, SHA256d y RIPEMD160.
- k256: para firma digital con ECDSA (Elliptic Curve Digital Signature Algorithm).
- secp256k1: variante para ECDSA (Elliptic Curve Digital Signature Algorithm).
- bs58: para serializacion en base58.
Material de consulta
- Sitio Bitcoin Developer: https://developer.bitcoin.org
- Protocol Documentation Wiki: https://en.bitcoin.it/wiki/Protocol_documentation
- Programming Bitcoin, Jimmy Song, O’Reilly 2019: https://www.oreilly.com/library/view/programming-bitcoin/9781492031482/
Criterios de Aceptación y Corrección del Proyecto
Para el desarrollo del proyecto, se deberá observar los siguientes lineamientos generales:
- Testing: Se deberá implementar testing unitario automatizado, utilizando las herramientas de Rust de los métodos y funciones relevantes implementados. Se deberán implementar tests de integración automatizados.
- Manejo de Errores: Deberá hacerse un buen uso y administración de los casos de error, utilizando para ello, las estructuras y herramientas del lenguaje, escribiendo en forma lo más idiomática posible su tratamiento.
- Control de versiones: Se deberá utilizar la herramienta git, siguiendo las recomendaciones de la cátedra. En particular, se deberá utilizar la metodología GitHub Flow para el trabajo con ramas (branches) y la entrega continua del software.
- Trabajo en equipo: Se deberá adecuar, organizar y coordinar el trabajo al equipo, realizando tareas como revisión de código cruzada entre pares de una funcionalidad en un pull request de git.
- Merge de Branchs: Para poder hacer el merge de un branch de una funcionalidad, todos los tests pasan de forma satisfactoria
- Informe final: El trabajo debe acompañarse por un informe que debe incluir diagramas de secuencia de las operaciones más relevantes, diagrama de componentes y módulos de la arquitectura general del diseño desarrollado, todos acompañados de la explicación respectiva.
Evaluaciones
El desarrollo del proyecto tendrá un seguimiento directo semanal por parte del docente a cargo del grupo.
Se deberá desarrollar y presentar los avances y progreso del trabajo semana a semana (simulando un sprint de trabajo). Cada semana, cada docente realizará una valoración del estado del trabajo del grupo.
El progreso de cada semana deberá ser acorde a lo que se convenga con el docente para cada sprint. Si el mismo NO cumple con la cantidad de trabajo requerido, el grupo podrá estar desaprobado de forma prematura de la materia, a consideración del docente.
Hacia la mitad del desarrollo del proyecto se deberá entregar una versión preliminar que deberá cumplir con un conjunto de requisitos a definir por la cátedra en las próximas semanas. Dichos requisitos serán de cumplimiento mínimo y obligatorio, aquellos grupos que lo deseen podrán implementar requisitos adicionales.
Nota importante: Se deja constancia que las funcionalidades requeridas por este enunciado son un marco de cumplimiento mínimo y que pueden haber agregados o modificaciones durante el transcurso del desarrollo por parte del docente a cargo, que formarán parte de los requerimientos a cumplir. Cabe mencionar que estos desvíos de los requerimientos iniciales se presentan en situaciones reales de trabajo con clientes.
Finalización del Proyecto
El desarrollo del proyecto finaliza el último día de clases del cuatrimestre. En esa fecha, cada grupo deberá realizar una presentación final y se hará una evaluación global del trabajo.
En dicha presentación se deberá detallar la arquitectura del proyecto, aprendizajes del mismo, y realizar una muestra funcional del desarrollo, esto es una "demo" como si fuera para el usuario final.
El trabajo debe acompañarse por un informe que debe constar de los puntos detallados precedentemente, diagramas de secuencia de las operaciones más relevantes, diagrama de componentes y módulos de la arquitectura general del diseño desarrollado, todos acompañados de la explicación respectiva.
Agregado Final 2023C1: Nodo como servidor
Introducción
Durante el cuatrimestre se desarrolló un proyecto de mediana envergadura en Rust, donde se implementó un Nodo de Bitcoin con funcionalidades acotadas. Para este final se propone acoplar a lo realizado durante el cuatrimestre un agregado donde el Nodo tambien tenga la funcionalidad de actuar como servidor, recibiendo conexiones entrantes de otros nodos clientes por el puerto que indica el protocolo.
Requerimientos funcionales
El Nodo Bitcoin, además de cumplir con los requerimientos funcionales y no funcionales establecidos en el enunciado del Trabajo Practico, debera actuar como servidor, recibiendo conexiones entrantes de otros nodos y respondiendo a las solicitudes que estos realicen. Para ello debera cumplir con las siguientes funcionalidades:
- Recibir conexiones entrantes en el puerto definido para la red
testnet, el cual sera establecido en el archivo de configuracion. - Atender a estas conexiones como indica el protocolo, es decir realizando el
Handshake. - Responder a las solicitudes de
Headersrealizadas mediante el mensajegetheaderscomo indica el protocolo. - Responder a los mensajes
getdatasegun indica el protocolo. - (opcional) Notificar al nodo cliente sobre nuevos bloques y transacciones recibidas desde otros nodos.
- Se debe poder visualizar el estado de la descarga en la interfaz grafica.
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución del proyecto:
- El proyecto deberá ser desarrollado en lenguaje Rust, usando las herramientas de la biblioteca estándar.
- Se deben implementar tests unitarios y de integración de las funcionalidades que se consideren más importantes.
- El código fuente debe compilarse en la versión stable del compilador y no se permite utilizar bloques unsafe.
- La compilación no debe arrojar warnings del compilador, ni del linter clippy.
- Las funciones y los tipos de datos (struct) deben estar documentadas siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- El programa deberá funcionar en ambiente Unix / Linux.
- No se permite utilizar crates externos.
Presentación
Se deberá realizar una presentacion explicando la implementacion de este agregado, incluyendo las decisiones de diseño y una demostración de la funcionalidad. Para cumplir con los requisitos minimos de este agregado se debera verificar el funcionamiento del nodo actuando como servidor. Para ello los alumnos deberan demostrar durante su presentacion la correcta ejecucion del programa y la descarga completa del Initial Block Download (IBD). La prueba se realizara ejecutando dos instancias de la aplicacion: la primera de ellas conectada a la red principal y teniendo previamente descargada una parte de la blockchain y la segunda, sin datos descargados, tendra su archivo de configuracion modificado para conectarse a la primera e iniciar la descarga de la blockchain. Deberan contemplar las modificaciones necesarias para que el nodo se pueda conectar tanto a direcciones DNS como a direcciones IP definidas en el archivo de configuracion.
Nota: Se permite realizar la demostracion ejecutando las dos instancias en el mismo Host, en cuyo caso la segunda instancia se conectara a localhost o 127.0.0.1.
Importante: cada grupo debera hacer uso de las herramientas de que dispone para demostrar en vivo la correcta descarga completa de la bockchain, ya sea comparando archivos de headers y bloques y/o mediante el uso de la interfaz grafica.
Fechas de final
El grupo deberá presentarse en una de las fechas de examen final, tal como se publica en el calendario respectivo.
- 03/07
- 24/07
- 31/07
- 07/08
- 14/08
Proyecto: Git Rústico - 2do Cuatrimestre 2023
Introducción a Git
Git es un sistema de control de versiones distribuido que se utiliza para rastrear cambios en el código fuente de un proyecto a lo largo del tiempo. Permite a múltiples personas colaborar en un proyecto, realizar seguimiento de cambios y fusionar contribuciones de diferentes desarrolladores de manera eficiente.
Objetivo del Proyecto
El objetivo principal del presente proyecto de desarrollo consiste en la implementación de un Cliente y Servidor Git con funcionalidades acotadas que se detallan en el presente enunciado. Siguiendo las guías de desarrollo y especificaciones de Git.
El objetivo secundario del proyecto consiste en el desarrollo de un proyecto real de software de mediana envergadura aplicando buenas prácticas de desarrollo de software, incluyendo entregas y revisiones usando un sistema de control de versiones.
Se espera que se haga un uso lo más idiomático posible del lenguaje de programación Rust, siguiendo los estándares que éste promueve.
Requerimientos funcionales
Los siguientes son los requerimientos funcionales para el desarrollo del Trabajo.
- Clonación de repositorios: El cliente Git deberá ser capaz de clonar repositorios remotos en la máquina local, incluyendo la historia de commits y ramas.
- Comandos básicos: El cliente deberá permitir la ejecución de comandos básicos de Git, como agregar cambios (add), realizar commits, subir cambios (push) y descargar cambios (pull). Los comandos requeridos estan detallados en la sección: Implementación del Cliente Git.
- Servidor: El servidor debera soportar el protocolo Git transport permitiendo al cliente descargar el contenido necesario respetando la implementacion de upload-pack y receive-pack
- Interfaz gráfica: Se debe implementar una interfaz gráfica simple para visualizar la historia de commits, gestionar ramas y realizar operaciones básicas. La apariencia puede ser similar a la interfaz de GitKraken.
- Archivo de Configuración: El cliente Git deberá poder ser configurado mediante un archivo de configuración, de manera similar al archivo "gitconfig" de Git. Este archivo deberá incluir información como el nombre y correo del usuario.
- Archivo de Log: El cliente Git debe mantener un registro de las acciones realizadas y mensajes relevantes en un archivo de log. La ubicación del archivo de log estará especificada en el archivo de configuración. Como requerimiento particular del Proyecto, NO se considerará válido que el servidor mantenga un file handle global, aunque esté protegido por un lock, y que se escriba directamente al file handle. La arquitectura deberá contemplar otra solución.
Implementación del Cliente Git
El cliente Git debe permitir realizar las operaciones basicas de manejo de repositorios, incluyendo crear repositorios, clonar repositorios existentes, actualizar la informacion local del repositorio y enviar las actualizaciones al servidor (commits, branches, etc.). Para cumplir con este objetivo se deberan implementar los comandos detallados en el listado siguiente, en el cual se distinguen comandos requeridos para la entrega intermedia y comandos requeridos para la entrega final.
Es importante destacar que estos comandos soportan una amplia diversidad de parametros y modificadores que complejizan su implementacion, por este motivo en el presente trabajo nos concentraremos en la funcionalidad basica de cada uno de ellos, siempre que esto sea suficiente para cumplir con los casos de uso tipicos de la herramienta (cada grupo debera analizar y validar con sus correctores las decisiones tomadas respecto a este punto)
A continuacion se listan los comandos requeridos:
Comandos requeridos para la entrega intermedia:
- hash-object (git man page)
- cat-file (git man page)
- init (git man page)
- status (git man page)
- add (git man page)
- rm (git man page)
- commit (git man page)
- checkout (git man page)
- log (git man page)
- clone (git man page)
- fetch (git man page)
- merge (git man page)
- remote (git man page)
- pull (git man page)
- push (git man page)
- branch (git man page)
Comandos requeridos para la entrega final:
- check-ignore (git man page)
- ls-files (git man page)
- ls-tree (git man page)
- show-ref (git man page)
- rebase (git man page)
- tag (git man page)
Nota: Durante el desarrollo del cliente se recomienda utilizar el servicio de git daemon para poder realizar pruebas conectando a un servidor git real.
Implementación del Servidor Git
El Servidor permitirá al cliente descargar el contenido del repositorio respetando la implementacion de upload-pack y recibir actualizaciones de contenido por parte de los clientes mediante receive-pack siguiendo el protocolo Git Transport. Estas operaciones serán utilizadas por el cliente para implementar los comandos que interactuan con el Servidor, como por ejemplo fetch, pull, push, etc. A continuacion se puede observar un diagrama que representa la interaccion entre distintos Clientes que se conectan al Servidor:
Importante: El Servidor deberá ser capaz de atender solicitudes de multiples clientes al mismo tiempo, para lo cual se pide utilizar multiples threads de manera de paralelizar el trabajo del Servidor. No se considerara válida una implementacion en la cual la peticion de un cliente deba esperar a que finalice el procesamiento de peticiones previas de otros clientes.
En los casos en los que se presenten un conflictos entre cambios realizados por un cliente y cambios realizados por otro se deben resolver estos conflictos siguiendo el estandar del protocolo git.
Interfaz gráfica
Se debe implementar una interfaz gráfica utilizando la biblioteca GTK, mediante el crate gtk-rs. Se recomienda utilizar Glade y GTK3.
La interfaz gráfica debe permitir al usuario realizar todas las operaciones soportadas por el cliente (comandos requeridos) y visualizar la historia de commits y branches en forma grafica de manera similar a como se puede observar en cualquier herramienta comercial, como por ejemplo GitKraken
En los casos en los que se presente un conflicto entre commits la interfaz debe permitir en forma grafica visualizar y resolver estos conflictos.
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución del proyecto:
- El proyecto deberá ser desarrollado en lenguaje Rust, utilizando las herramientas de la biblioteca estándar.
- Se deben implementar pruebas unitarias y de integración de las funcionalidades que se consideren más importantes.
- El código fuente debe compilar en la versión estable del compilador y no se permite el uso de bloques inseguros (unsafe).
- El código deberá funcionar en ambiente Unix / Linux.
- La compilación no debe generar advertencias del compilador ni del linter clippy.
- Las funciones y los tipos de datos (struct) deben estar documentados siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- Las funciones no deben tener una extensión mayor a 30 líneas. Si se requiere una extensión mayor, se debe particionar en varias funciones.
- Cada tipo de dato implementado debe ser colocado en una unidad de compilación (archivo fuente) independiente.
Entrega intermedia
Los alumnos deberan realizar una entrega intermedia, la cual deberá incluir los siguientes puntos desarrollados en la sección Requerimientos funcionales:
- Clonación de repositorios
- Comandos básicos (init, status, add, commit, push, pull) detallados en el listado de comandos requeridos para la entrega intermedia
- Implementación de una interfaz gráfica simple para la gestión de commits y ramas.
La entrega se realizará en forma de Demostración (Demo) en la cual los alumnos deberán abarcar los siguientes puntos:
Explicación general de la solución, incluyendo diagramas que muestren el diseño desarrollado. Recorrido por el código fuente escrito, explicando los principales contenidos de cada módulo. Demo en vivo del programa, en donde se comprobará que el programa cumple con los puntos solicitados. Ademas se debe demostrar que el cliente desarrollado puede conectarse indistintamente a su propio servidor como tambien a un servidor iniciado con git daemon
Todos los miembros del grupo deberán participar de la demo y explicar su participación en el proyecto, incluyendo detalles de implementación.
Crates externos permitidos
Se permite el uso de los siguientes crates solo para los usos mencionados (siempre y cuando se los considere necesario):
rand: para la generación de valores aleatorios.chrono: para la obtención del timestamp actual.cryptoosha1: para la función de hash SHA1.libflateoflate2: para comprimir y descomprimir contenidos.gtk-rs: para la implementación de la interfaz gráfica.
Material de consulta
- Sitio oficial de Git: https://git-scm.com/
- Pro Git, Scott Chacon y Ben Straub: https://git-scm.com/book/en/v2
- Documentación de Rust: https://doc.rust-lang.org/
Criterios de Aceptación y Corrección del Proyecto
Para el desarrollo del proyecto, se deberá observar los siguientes lineamientos generales:
- Testing: Se deberá implementar testing unitario automatizado, utilizando las herramientas de Rust de los métodos y funciones relevantes implementados. Se deberán implementar tests de integración automatizados.
- Manejo de Errores: Deberá hacerse un buen uso y administración de los casos de error, utilizando para ello, las estructuras y herramientas del lenguaje, escribiendo en forma lo más idiomática posible su tratamiento.
- Control de versiones: Se deberá utilizar la herramienta git, siguiendo las recomendaciones de la cátedra. En particular, se deberá utilizar la metodología GitHub Flow para el trabajo con ramas (branches) y la entrega continua del software.
- Trabajo en equipo: Se deberá adecuar, organizar y coordinar el trabajo al equipo, realizando tareas como revisión de código cruzada entre pares de una funcionalidad en un pull request de git.
- Merge de Branchs: Para poder hacer el merge de un branch de una funcionalidad, todos los tests pasan de forma satisfactoria
- Informe final: El trabajo debe acompañarse por un informe que debe incluir diagramas de secuencia de las operaciones más relevantes, diagrama de componentes y módulos de la arquitectura general del diseño desarrollado, todos acompañados de la explicación respectiva.
Evaluación
El desarrollo del proyecto tendrá un seguimiento directo semanal por parte del docente a cargo del grupo.
Se deberá desarrollar y presentar los avances y progreso del trabajo semana a semana (simulando un sprint de trabajo). Cada semana, cada docente realizará una valoración del estado del trabajo del grupo.
El progreso de cada semana deberá ser acorde a lo que se convenga con el docente para cada sprint. Si el mismo NO cumple con la cantidad de trabajo requerido, el grupo podrá estar desaprobado de forma prematura de la materia, a consideración del docente.
Hacia la mitad del desarrollo del proyecto se deberá entregar una versión preliminar que deberá cumplir con los requisitos mencionados en el apartado Entrega intermedia anteriormente enunciado. Estos requisitos son de cumplimiento mínimo y obligatorio, aquellos grupos que lo deseen podrán implementar requisitos adicionales.
Nota importante: Se deja constancia que las funcionalidades requeridas por este enunciado son un marco de cumplimiento mínimo y que pueden haber agregados o modificaciones durante el transcurso del desarrollo por parte del docente a cargo, que formarán parte de los requerimientos a cumplir. Cabe mencionar que estos desvíos de los requerimientos iniciales se presentan en situaciones reales de trabajo con clientes.
Finalización del Proyecto
El desarrollo del proyecto finaliza el último día de clases del cuatrimestre. En esa fecha, cada grupo deberá realizar una presentación final y se hará una evaluación global del trabajo.
En dicha presentación se deberá detallar la arquitectura del proyecto, aprendizajes del mismo, y realizar una muestra funcional del desarrollo, esto es una "demo" como si fuera para el usuario final.
El trabajo debe acompañarse por un informe que debe constar de los puntos detallados precedentemente, diagramas de secuencia de las operaciones más relevantes, diagrama de componentes y módulos de la arquitectura general del diseño desarrollado, todos acompañados de la explicación respectiva.
Fechas de entrega
Entrega intermedia: Lunes 6 de Noviembre de 2023
Entrega final de la cursada: Lunes 4 de Diciembre de 2023
Estas entregas serán presenciales en la sede de la Facultad.
Agregado Final 2023C2: Pull Requests
Introducción
Durante el cuatrimestre se desarrolló un proyecto de mediana envergadura en Rust, donde se implementó un Cliente y un Servidor de Git. Para este final se propone acoplar a lo realizado durante el cuatrimestre un agregado donde el Servidor incorpore una API web para la administración de Pull Requests.
Requerimientos funcionales
El Servidor, además de cumplir con los requerimientos funcionales y no funcionales establecidos en el enunciado del Trabajo Práctico, deberá exponer una API web en un puerto indicado por configuración, por el cual recibirá Requests respetando el protocolo HTTP para realizar las siguientes operaciones:
- Crear un Pull Requests:
POST /repos/{repo}/pulls. Ver especificación de referencia. - Listar Pull Requests:
GET /repos/{repo}/pulls. Ver especificación de referencia. - Obtener un Pull Requests:
GET /repos/{repo}/pulls/{pull_number}. Ver especificación de referencia. - Listar commits en un Pull Request
GET repos/{repo}/pulls/{pull_number}/commits. Ver especificación de referencia. - Realizar el merge de un Pull Request
PUT /repos/{repo}/pulls/{pull_number}/merge. Ver especificación de referencia. - (opcional) Modificar un Pull Requests:
PATCH /repos/{repo}/pulls/{pull_number}. Ver especificación de referencia. - (opcional) Soportar mas de un media type.
Como mínimo se pide implementar el media type: application/json
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución del proyecto:
- El proyecto deberá ser desarrollado en lenguaje Rust, usando las herramientas de la biblioteca estándar.
- Se deben implementar tests unitarios y de integración de las funcionalidades que se consideren más importantes.
- El código fuente debe compilarse en la versión stable del compilador y no se permite utilizar bloques unsafe.
- La compilación no debe arrojar warnings del compilador, ni del linter clippy.
- Las funciones y los tipos de datos (struct) deben estar documentadas siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- El programa deberá funcionar en ambiente Unix / Linux.
- Solo se permite el uso crates externos listados en la sección correspondiente.
Presentación
Se deberá realizar una presentación explicando la implementación de este agregado, incluyendo las decisiones de diseño y una demostración de la funcionalidad. Dentro de los detalles de implementación se deberá explicar la solución adoptada desde el punto de vista de multi-threading y performance, con diagramas que faciliten la explicación. Para cumplir con los requisitos mínimos de este agregado se deberá verificar el funcionamiento todas las APIs listadas en la sección de requerimientos funcionales. Para ello los alumnos podrán elegir una herramienta para realizar los requests en vivo o en su defecto utilizar el comando curl. Los requests a realizar durante la demo en vivo deberán estar preparados con anterioridad y guardados en algún archivo del repositorio para poder ser utilizados durante la corrección del presente trabajo.
Crates externos permitidos
Además de los crates permitidos en el enunciado del Trabajo Práctico se permite el uso de los siguientes crates solo para la implementación del presente agregado:
serde: para la serializacion y deserializacion del payload de mensaje HTTP.serde_json: para la serializacion y deserializacion utilizando JSON.
Fechas de final
El grupo deberá presentarse en una de las fechas de examen final, tal como se publica en el calendario respectivo.
Agregado Final 2023C2: Releases
Introducción
Durante el cuatrimestre se desarrolló un proyecto de mediana envergadura en Rust, donde se implementó un Cliente y un Servidor de Git. Para este final se propone acoplar a lo realizado durante el cuatrimestre un agregado donde el Servidor incorpore una API web para la administración de Releases.
Requerimientos funcionales
El Servidor, además de cumplir con los requerimientos funcionales y no funcionales establecidos en el enunciado del Trabajo Práctico, deberá exponer una API web en un puerto indicado por configuración, por el cual recibirá Requests respetando el protocolo HTTP para realizar las siguientes operaciones:
- Crear un Release:
POST /repos/{repo}/releases. Ver especificación de referencia. - Listar Releases:
GET /repos/{repo}/releases. Ver especificación de referencia. - Obtener el último Release:
GET /repos/{repo}/releases/latest. Ver especificación de referencia. - Obtener un Release buscando por Tag:
GET /repos/{repo}/releases/tags/{tag}. Ver especificación de referencia. - Generar notas de Release:
POST /repos/{repo}/releases/generate-notes. Ver especificación de referencia. - (opcional) Modificar un Release:
PATCH /repos/{repo}/releases/{release_id}. Ver especificación de referencia. - (opcional) Eliminar un Release:
DELETE /repos/{repo}/releases/{release_id}. Ver especificación de referencia. - (opcional) Soportar mas de un media type.
Como mínimo se pide implementar el media type: application/json
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución del proyecto:
- El proyecto deberá ser desarrollado en lenguaje Rust, usando las herramientas de la biblioteca estándar.
- Se deben implementar tests unitarios y de integración de las funcionalidades que se consideren más importantes.
- El código fuente debe compilarse en la versión stable del compilador y no se permite utilizar bloques unsafe.
- La compilación no debe arrojar warnings del compilador, ni del linter clippy.
- Las funciones y los tipos de datos (struct) deben estar documentadas siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- El programa deberá funcionar en ambiente Unix / Linux.
- Solo se permite el uso crates externos listados en la sección correspondiente.
Presentación
Se deberá realizar una presentación explicando la implementación de este agregado, incluyendo las decisiones de diseño y una demostración de la funcionalidad. Dentro de los detalles de implementación se deberá explicar la solución adoptada desde el punto de vista de multi-threading y performance, con diagramas que faciliten la explicación. Para cumplir con los requisitos mínimos de este agregado se deberá verificar el funcionamiento todas las APIs listadas en la sección de requerimientos funcionales. Para ello los alumnos podrán elegir una herramienta para realizar los requests en vivo o en su defecto utilizar el comando curl. Los requests a realizar durante la demo en vivo deberán estar preparados con anterioridad y guardados en algún archivo del repositorio para poder ser utilizados durante la corrección del presente trabajo.
Crates externos permitidos
Además de los crates permitidos en el enunciado del Trabajo Práctico se permite el uso de los siguientes crates solo para la implementación del presente agregado:
serde: para la serializacion y deserializacion del payload de mensaje HTTP.serde_json: para la serializacion y deserializacion utilizando JSON.
Fechas de final
El grupo deberá presentarse en una de las fechas de examen final, tal como se publica en el calendario respectivo.
Proyecto: BitTorrent - 1er Cuatrimestre 2022
¡IMPORTANTE!
Se modificó la lista de crates externos permitidos, agregando opciones para la conexión cifrada con el tracker, para logging y para obtención de timestamp, entre otros. Chequear la sección Crates externos permitidos.
Introducción
BitTorrent es un protocolo de capa de aplicación de arquitectura P2P que se utiliza para transferencia de archivos entre múltiples dispositivos que se denominan peers. Debido a su arquitectura, BitTorrent es un protocolo escalable ya que no tiene un único punto de falla, más bien todos los peers garantizan la transferencia de un archivo de un nodo de la red a otro. Se denomina torrent al conjunto de peers que participan en la distribución de un archivo en particular.
Para transferir un archivo a este se lo separa en chunks de igual tamaño y varios peers pueden transferir varios chunks de manera simultánea. Cuando un peer se suma a un torrent, inicialmente no tiene el archivo, e irá progresivamente recibiendo chunks hasta tenerlo por completo.
La documentación oficial del proyecto BitTorrent se encuentra en: https://www.bittorrent.org/.
Objetivo del Proyecto
El objetivo del proyecto es implementar un Cliente BitTorrent con funcionalidades acotadas, que se detallan en el presente enunciado.
El objetivo secundario del proyecto consiste en el desarrollo de un proyecto real de software de mediana envergadura aplicando buenas prácticas de desarrollo de software, incluyendo entregas y revisiones usando un sistema de control de versiones.
Se espera que se haga un uso lo más idiomático posible del lenguaje de programación, siguiendo los estándares que éste promueve.
Criterios de Aceptación y Corrección del Proyecto
Para el desarrollo del proyecto, se deberá observar los siguientes lineamientos generales:
- [Testing] Se deberá implementar testing unitario automatizado, utilizando las herramientas de Rust de los métodos y funciones relevantes implementados. Se deberán implementar tests de integración automatizados.
- [Manejo de Errores] Deberá hacerse un buen uso y administración de los casos de error, utilizando para ello, las estructuras y herramientas del lenguaje, escribiendo en forma lo más idiomática posible su tratamiento.
- [Control de versiones] Se deberá utilizar la herramienta git, siguiendo las recomendaciones de la cátedra. En particular, se deberá utilizar la metodología GitHub Flow para el trabajo con ramas (branches) y la entrega continua del software.
- [Trabajo en equipo] Se deberá adecuar, organizar y coordinar el trabajo al equipo, realizando tareas como revisión de código cruzada entre pares de una funcionalidad en un pull request de git.
- [Merge de Branchs] Para poder hacer el merge de un branch de una funcionalidad, todos los tests pasan de forma satisfactoria.
Evaluaciones
El desarrollo del proyecto tendrá un seguimiento directo semanal por parte del docente a cargo del grupo.
Se deberá desarrollar y presentar los avances y progreso del trabajo semana a semana (simulando un sprint de trabajo). Cada semana, cada docente realizará una valoración del estado del trabajo del grupo.
El progreso de cada semana deberá ser acorde a lo que se convenga con el docente para cada sprint. Si el mismo NO cumple con la cantidad de trabajo requerido, el grupo podrá estar desaprobado de forma prematura de la materia, a consideración del docente.
Hacia la mitad del desarrollo del proyecto se deberá entregar una versión preliminar que deberá cumplir con un conjunto de requisitos a definir por la cátedra en las próximas semanas. Dichos requisitos serán de cumplimiento mínimo y obligatorio, aquellos grupos que lo deseen podrán implementar requisitos adicionales.
Nota importante: Se deja constancia que las funcionalidades requeridas por este enunciado son un marco de cumplimiento mínimo y que pueden haber agregados o modificaciones durante el transcurso del desarrollo por parte del docente a cargo, que formarán parte de los requerimientos a cumplir. Cabe mencionar que estos desvíos de los requerimientos iniciales se presentan en situaciones reales de trabajo con clientes.
Finalización del Proyecto
El desarrollo del proyecto finaliza el último día de clases del cuatrimestre. En esa fecha, cada grupo deberá realizar una presentación final y se hará una evaluación global del trabajo.
En dicha presentación se deberá detallar la arquitectura del proyecto, aprendizajes del mismo, y realizar una muestra funcional del desarrollo, esto es una "demo" como si fuera para el usuario final.
El trabajo debe acompañarse por un informe que debe constar de los puntos detallados precedentemente, diagramas de secuencia de las operaciones más relevantes, diagrama de componentes y módulos de la arquitectura general del diseño desarrollado, todos acompañados de la explicación respectiva.
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución del proyecto:
- El proyecto deberá ser desarrollado en lenguaje Rust, usando las herramientas de la biblioteca estándar.
- Se deben implementar tests unitarios y de integración de las funcionalidades que se consideren más importantes.
- No se permite utilizar crates externos más allá de los mencionados en dicha sección.
- El código fuente debe compilarse en la versión stable del compilador y no se permite utilizar bloques unsafe.
- El código deberá funcionar en ambiente Unix / Linux.
- El programa deberá ejecutarse en la línea de comandos.
- La compilación no debe arrojar warnings del compilador, ni del linter clippy.
- Las funciones y los tipos de datos (struct) deben estar documentadas siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- Las funciones no deben tener una extensión mayor a 30 líneas. Si se requiriera una extensión mayor, se deberá particionarla en varias funciones.
- Cada tipo de dato implementado debe ser colocado en una unidad de compilación (archivo fuente) independiente.
Crates externos permitidos
Se permite el uso de los siguientes crates sólo para los usos mencionados (siempre y cuando se los considere necesario):
rand: para la generación de valores aleatorios.chrono: para la obtención del timestamp actual.log(con alguna implementación a elección entresimple_logger,env_loggerypretty_env_logger): para logging por consola. No se permite usar ningún crate para loggear en archivos, esto deberá ser implementado aparte.cryptoosha1: para la función SHA1, se pueden utilizar las mismas de los crates mencionados.native-tls: para la conexión cifrada con el tracker.
Requerimientos funcionales
Los siguientes son los requerimientos funcionales para el desarrollo del Trabajo.
El cliente de BitTorrent deberá permitir descargar más de un archivo por vez en una misma ejecución. Todos los archivos torrent deseados se deberán suministrar como parámetro al momento de la ejecución del programa. Se puede optar por suministrar la ruta a un directorio (en lugar de un archivo) como parámetro, de forma que se deberá leer todos los archivos torrent existentes en el mismo.
Como mínimo, se debe soportar la posibilidad de archivos torrent de tipo single-file (es decir, conteniendo un único archivo). Se espera y es deseable que sea implementada la funcionalidad que sea capaz de descargar torrent que contengan múltiples archivos.
Protocolo
El protocolo a implementar corresponde a la versión 1.0, cuya especificacion oficial se encuentra en: http://bittorrent.org/beps/bep_0003.html
Sin embargo, dado que la misma carece de detalles de implementación, utilizaremos la siguiente especificación no oficial para obtener mayor nivel de detalle: https://wiki.theory.org/BitTorrentSpecification
A continuación se muestra un ejemplo de comunicación entre el cliente (BT client), el tracker y uno de los peers (BT peer):
![]()
Funcionalidades del cliente
Configuración
El cliente BitTorrent debe poder ser configurado mediante un archivo de configuración.
Las opciones de configuración mínimas son:
- puerto TCP en el que se reciben conexiones de otros peers.
- ruta al directorio de logs.
- ruta al directorio de descargas de archivos.
Arquitectura
Se debe implementar la arquitectura de tipo cliente / servidor para el correcto funcionamiento de las descargas de archivos y la transmisión a terceras partes desde el mismo cliente como fuente emisora (seed), en este actúa como servidor.
Logs
El cliente BitTorrent debe mantener un registro de las acciones realizadas y los eventos ocurridos en un archivo de log. Se debe escribir en el log cada vez que se complete una pieza de uno de los archivos descargados.
La ubicación del archivo de log estará especificada en el archivo de configuración. Como requerimiento particular del Proyecto, NO se considerará válido que el servidor mantenga un file handle global, aunque esté protegido por un lock, y que se escriba directamente al file handle. La arquitectura deberá contemplar otra solución.
Almacenamiento de la descarga
Cada grupo puede optar en su solución por la estrategia de almacenamiento del archivo descargado tal como lo desee. Una estrategia consiste en reservar y escribir de forma inicial en el disco la totalidad del tamaño de los archivos que componen al torrent y luego sobre-escribir cada byte con el correspondiente al archivo a medida que se descarga. La otra opción consiste en coleccionar todas las piezas del archivo que se descarga (o de los múltiples archivos que componen al torrent) en un almacenamiento temporal y realizar un ensamblado al finalizar la descarga.
Procesamiento del archivo .torrent
El archivo .torrent contiene la metadata esencial para el funcionamiento de la descarga por BitTorrent. Se representa con un diccionario codificado con el formato Bencoding que contiene toda la información referida al torrent.
Para este trabajo nos centraremos principalmente en las claves announce e info, las cuales contienen la URL del Tracker y la información del contenido de la descarga, ya sea un único archivo o múltiples archivos y directorios. Para más detalles consultar la especificación.
Comunicación con el Tracker
La comunicación con el Tracker se realiza a través del protocolo HTTP, enviando los parámetros por querystring. La respuesta se encuentra codificada con el formato Bencoding.
A continuación se detalla la información a enviar en el request y los valores de respuesta:
Tracker Request
Se realiza mediante un request HTTP GET a la url de announce especificada en el archivo .torrent, enviando los siguiente parámetros por querystring:
info_hash: Valor de 20 bytes resultante de aplicar el algoritmo SHA-1 al valor info del archivo .torrent, encodeado con urlencode.peer_id: Cadena de 20 bytes utilizada como identificador único del cliente encodeada con urlencode.port: Número de puerto en el cual el cliente escucha conexiones.ip: Opcional. Dirección IP del cliente.uploaded: Número que indica la cantidad de bytes subidos hasta el momento.downloaded: Número que indica la cantidad de bytes descargados hasta el momento.left: Número de bytes pendientes por descargar.event: Cadena de caracteres que indica el estado en el que se encuentra el cliente. Puede ser: started, completed o stopped.
Tracker Response
El tracker responde las peticiones con un diccionario tipo Bencoded con los siguientes datos:
interval: Tiempo en segundos que el cliente tiene que esperar para mandar peticiones al tracker.complete: Número con que indica la cantidad de seeds.incomplete: Número con que indica la cantidad de leechers.peers: Lista de diccionarios con los siguientes valores: peer id, dirección IP y puerto.peer_id: Cadena de 20 bytes utilizada como identificador único del cliente.ip: Cadena de caracteres con la dirección IP o nombre de DNS del peerport: Número entero con el puerto que escucha el peer.
Mensajes P2P que se deberán soportar
A continuación se detalla el contenido y significado de cada tipo de mensaje indicando:
<longitud del mensaje><tipo del mensaje>[<información útil>]
keep alive:<0>Se envía para mantener la conexión viva si ningún otro mensaje ha sido enviado durante 2 minutos.choke:<1><0>El emisor comunica al receptor que lo ha bloqueado, es decir, que no le servirá ninguna petición pendiente o futura.unchoke:<1><1>El emisor comunica al receptor que lo ha desbloqueado y que responderá a las peticiones.interested:<1><2>El emisor comunica al receptor que está interesado en alguna de sus piezas.not interested:<1><3>El emisor comunica al receptor que no está interesado en ninguna de sus piezas.have:<5><4><índice de pieza>El índice de pieza son 4 bytes en decimal. El emisor comunica al receptor que tiene una pieza determinada. Este mensaje lo envía el peer local a todos los peers conocidos cada vez que consigue descargar una pieza nueva.bitfield:<1+X><5><bitfield>El emisor envía al receptor una secuencia de bytes de tamaño X que representa un campo de bits indicando qué piezas tiene (bit a 1) y cuales no (bit a 0). Leyendo los bits de izquierda a derecha, el primer byte corresponde a las piezas 0-7, el segundo corresponde a las piezas 8-15. Los bits del final que no se usan se ponen a 0. Este es el primer mensaje que se envía en la conexión P2P. Los peers sin ninguna pieza pueden obviar el envío de este mensaje.request:<13><6><índice de pieza><comienzo><longitud>Cada uno de los tres campos que aparecen después del tipo del mensaje son 4 bytes en decimal. Estos campos describen un bloque que se encuentra en una pieza determinada, comienza en un byte dentro de ésta y tiene una determinada longitud. Este mensaje sirve para pedir un bloque al peer receptor.piece:<9+X><7><índice de pieza><comienzo><bloque>Cada uno de los dos primeros campos que aparecen después del tipo del mensaje son 4 bytes en decimal e indican la posición de un bloque dentro de una pieza. El tercer campo contiene el bloque, que es una secuencia de bytes de longitud X. Este mensaje sirve para enviar un bloque previamente solicitado por un peer remoto.cancel:<13><8><índice de pieza><comienzo><longitud>Cada uno de los tres campos que aparecen después del tipo del mensaje son 4 bytes en decimal y describen un bloque. Este mensaje normalmente se envía durante la fase End Game para cancelar peticiones duplicadas.
Interfaz gráfica
La aplicación cliente deberá contar con una interfaz gráfica que permita conocer el estado de las descargas de los torrents en curso.
Para realizar dicha aplicación, se debe utilizar el crate GTK. El grupo deberá investigar cómo utilizar dicho crate.
Requerimientos
La interfaz gráfica deberá contar con la siguientes pestañas:
- Pestaña de información general: Esta pestaña deberá contar con la información general de los torrents en curso, incluyendo: nombre y metadata del torrent (hash de verificación, tamaño total, cantidad de piezas, cantidad de peers, etc), estructura de archivos del torrent (ya sea un single file o una estructura de archivos y directorios) además del estado general de la descarga (porcentaje de completitud, cantidad de piezas descargadas y verificadas) y la cantidad de conexiones activas correspondiente a cada torrent.
- Pestaña de estadísticas de descarga: Esta pestaña deberá contar con todas las estadísticas de las descargas en curso, incluyendo: lista de Peers con ID, IP y puerto de cada una de las conexiones activas, velocidad de bajada y subida de cada conexión, estado del Peer (choked/unchoked, interested/not interested) y estado del cliente en el Peer (choked/unchoked, interested/not interested)
Aclaración importante: El diseño de la interfaz y cómo se acomodan los componentes de la misma estará a cargo de cada grupo y será validada por los tutores asignados.
Agregado al Proyecto - Finales Julio/Agosto 2022
Descargar agregado en formato PDF
Criterios de aprobación del Trabajo Práctico / Cursada de la materia
Para aprobar la cursada de la materia, se debe aprobar el Trabajo Práctico.
Estos son los criterios de aprobación:
- El software desarrollado funciona correctamente.
- Se puede testear en la red de Bit Torrent oficial.
- El proyecto debe estar debidamente documentado siguiendo los estándares de documentación de cargo doc.
- Se debe hace uso de las herramientas cargo fmt para formatear el código fuente y de cargo clippy para asegurar que el código es lo más idiomático posible. No debe haber warnings de clippy.
- El trabajo del grupo fue desarrollado con un esfuerzo constante y parejo a lo largo del cuatrimestre.
- Se cumplieron los objetivos planteados y comprometidos con los tutores en las reuniones de seguimiento.
- Se desarrollaron tests unitarios y de integración de las partes importantes del proyecto.
- Se hizo un uso correcto de la metodología de trabajo con Github.
Alcance de la entrega intermedia del Trabajo Práctico
Se deberá realizar una entrega intermedia el día 6 de Junio, la cual deberá cumplir con los los siguiente requerimientos:
- El programa deberá recibir por linea de comandos la ruta de un archivo .torrent
- El archivo .torrent debe ser leído y decodificado según el estándar y su información almacenada en memoria.
- Se deberá conectar al Tracker obtenido en el .torrent, decodificar la respuesta y obtener la lista de peers.
- Dada la lista de peers, deberá poder iniciar una conexión con al menos un peer y realizar el Handshake.
- Realizado el Handshake se debe iniciar el intercambio de mensajes para poder descargar una pieza del torrent.
- La pieza descargada se debe validar según el protocolo y almacenar en disco indicando el nro de pieza en el nombre de archivo.
- Implementación del Logger. (opcional - bonus point)
La entrega se realizara en forma de Demostración (Demo) en la cual los alumnos deberán abarcar los siguientes puntos:
- Explicación general de la solución, incluyendo diagramas que muestren el diseño desarrollado.
- Recorrido por el código fuente escrito, explicando los principales contenidos de cada módulo.
- Demo en vivo del programa, en donde se comprobará que el programa cumple con los puntos solicitados.
- Verificación en vivo de la integridad de la pieza descargada. (SHA1)
Nota: Todos los miembros del grupo deberán participar de la demo y explicar su participación en el proyecto, incluyendo detalles de implementación.
Proyecto IRC (Internet Rust Chat)
Objetivo
El objetivo del presente Trabajo Práctico consiste en el desarrollo de un servidor y un cliente de chat siguiendo los lineamientos del protocolo IRC.
Introducción
Internet Relay Chat (IRC) es un protocolo de mensajería de texto diseñado para conversaciones grupales, mediante el uso de canales, con soporte adicional para conversaciones uno a uno.
El protocolo funciona con un modelo cliente-servidor, donde los clientes se conectan a un servidor, que a su vez puede estar conectado a otros en una red de servidores.
La definición base de como funciona esta dada en documentos RFCs. El mayormente adoptado como base es el RFC1459, aunque la mayoría de las redes no se adecúan completamente a ninguna RFC.
Para el desarrollo del TP, utilizaremos la anterior mencionada RFC como el documento técnico con la descripción del trabajo. Además, dividiremos la entrega en dos etapas a desarrollar durante el cuatrimestre.
Recomendamos adicionalmente leer este pequeño documento que sirve de guía para leer las RFC
Desarrollo
Elementos del sistema
Servidor
Los servidores actúan como el lugar adonde los usuarios se conectan para hablar entre ellos. A su vez, un servidor puede conectarse con otros servidores, para armar una red IRC única, manteniendo una topología de spanning tree. La configuración de spanning tree, permite a mensajes viajar a traves de la red, sin que los servidores se tengan que preocupar porque los mismos entren en un loop y nunca dejen de ser re enviados.
Cliente
El cliente es la aplicación que permite al usuario conectarse a la red. Cada cliente en la red tiene un nickname de hasta 9 caracteres. Además, cada cliente tiene un hostname, un username, y un servidor asociado al cual esta conectado. El hostname es la IP o una dirección DNS y el username puede ser, por ejemplo, la primera parte de un email.
Canales
Los canales son grupos de clientes. Estos se crean cuando el primer cliente se une a uno, y se eliminan cuando el último sale. Cada canal tiene un nombre que debe comenzar con un & o un #, puede tener hasta 200 caracteres, y no puede contener espacios, el ASCII 7 (control+G) o comas, ya que estas son utilizadas como separadores por el protocolo.
Además los canales pueden ser distribuidos entre varios servidores, en cuyo caso se indican con #, o ser visibles por un solo servidor, en cuyo caso se indican con &. Además pueden tener varios modos adicionales que se indican en la especificación.
Operadores
Los operadores son los administradores (admins) de los servidores, pudiendo desconectarlos y conectarlos a la red, y además pueden bloquear (ban) y expulsar (kick) usuarios. El admin puede serlo de toda la red, o de un único servidor.
Operadores de canales
Los operadores de canales son admins de canales. Pueden expulsar clientes, invitarlos, y cambiar el modo del canal y su topic.
Mensajes
Los mensajes son el mecanismo de comunicación cliente-servidor y servidor-servidor.
Consisten de 3 partes: un prefijo, un comando, y sus parámetros.
Si existe un prefijo, este se indica con un caracter ":" (0x3b). El mismo se utiliza para los mensajes entre servidores para indicar el origen del mismo.
El comando puede ser cualquier comando IRC válido o 3 dígitos en ASCII.
El mensaje debe terminar con un CR-LF (Carriage return - Line Feed), y no puede exceder los 520 caracteres.
La descripción de los mensajes se da en formato BNF.
<message> ::= [':' <prefix> <SPACE> ] <command> <params> <crlf>
<prefix> ::= <servername> | <nick> [ '!' <user> ] [ '@' <host> ]
<command> ::= <letter> { <letter> } \| <number> <number> <number>
<SPACE> ::= ' ' { ' ' }
<params> ::= <SPACE> [ ':' <trailing> | <middle> <params> ]
<middle> ::= <Any *non-empty* sequence of octets not including SPACE or NUL or CR or LF, the first of which may not be ':'>
<trailing> ::= <Any, possibly *empty*, sequence of octets not including NUL or CR or LF>
<crlf> ::= CR LF
<target> ::= <to> [ "," <target> ]
<to> ::= <channel> | <user> '@' <servername> | <nick> | <mask>
<channel> ::= ('#' | '&') <chstring>
<servername> ::= <host>
<host> ::= see RFC 952 [DNS:4] for details on allowed hostnames
<nick> ::= <letter> { <letter> | <number> | <special> }
<mask> ::= ('#' | '$') <chstring>
<chstring> ::= <any 8bit code except SPACE, BELL, NUL, CR, LF and comma (',')>
<user> ::= <nonwhite> { <nonwhite> }
<letter> ::= 'a' ... 'z' | 'A' ... 'Z'
<number> ::= '0' ... '9'
<special> ::= '-' | '[' | ']' | '\' | '`' | '^' | '{' | '}'
Este formato see lee por ejemplo: "El comando es una letra y varias letras repetidas o 3 números" "El parámetro es un espacio y opcionalmente un ':' y un trailing o un middle y params"
Hitos del desarrollo del Proyecto
Entrega intermedia
Solicitamos para la primera entrega tener una aplicación servidor (actuando como servidor individual o single server) y una aplicación cliente que permita comunicar a múltiples usuarios conectados tanto en el mismo host (utilizando distinta configuración de puertos) como en distintos hosts.
Ambas aplicaciones deberan soportar los siguientes mensajes:
Conexión y Registración (RFC 1459 sección 4.1)
- Password message 4.1.1
- Nickname message 4.1.2
- User message 4.1.3
- Operator message 4.1.5
- Quit message 4.1.6
Intercambio de mensajes (RFC 1459 sección 4.4)
Channels (RFC 1459 sección 4.2)
Informacion de Usuarios (RFC 1459 sección 4.5)
Entrega final
Se incorporara el soporte para multiples servidores, que funcionaran basados en la topología de spanning tree.
Ademas de las funcionalidades de la entrega intermedia se agregara soporte a los siguientes mensajes:
Conexión y Registración (RFC 1459 sección 4.1)
Channels (RFC 1459 sección 4.2)
Other Features
- Away message 5.1
Interfaz gráfica
Se debe implementar una interfaz gráfica utilizando la biblioteca GTK, mediante el crate gtk-rs.
La interfaz deberá permitir el uso completo de las funcionalidades solicitadas y su apariencia deberá ser similar a la de cualquier software de mensajería de múltiples canales de los usados popularmente. Esto es, deberá mostrar una lista de canales, una lista de los usuarios del canal, los mensajes enviados en el canal y un espacio para escribir un mensaje en ese canal.
Evaluaciones
El desarrollo del proyecto tendrá un seguimiento directo semanal por parte del docente a cargo del grupo.
Se deberá desarrollar y presentar los avances y progreso del trabajo semana a semana (simulando un sprint de trabajo). Cada semana, cada docente realizará una valoración del estado del trabajo del grupo.
El progreso de cada semana deberá ser acorde a lo que se convenga con el docente para cada sprint. Si el mismo NO cumple con la cantidad de trabajo requerido, el grupo podrá estar desaprobado de forma prematura de la materia, a consideración del docente.
Se deja constancia que las funcionalidades requeridas por este enunciado son un marco de cumplimiento mínimo y que pueden haber agregados o modificaciones durante el transcurso del desarrollo por parte del docente a cargo, que formarán parte de los requerimientos a cumplir. Cabe mencionar que estos desvíos de los requerimientos iniciales se presentan en situaciones reales de trabajo con clientes.
Finalización del Proyecto
El desarrollo del proyecto finaliza el último día de clases del cuatrimestre. En esa fecha, cada grupo deberá realizar una presentación final y se hará una evaluación global del trabajo.
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución de los ejercicios:
- El proyecto deberá ser desarrollado en lenguaje Rust, usando las herramientas de la biblioteca estándar.
- No se permite utilizar crates externos. El único crate autorizado a ser utilizado es rand en caso de que se quiera generar valores aleatorios, además del crate de GTK mencionado anteriormente.
- El código fuente debe compilarse en la versión stable del compilador y no se permite utilizar bloques unsafe.
- El código deberá funcionar en ambiente Unix / Linux.
- El programa deberá ejecutarse en la línea de comandos.
- La compilación no debe arrojar warnings del compilador, ni del linter clippy.
- Las funciones y los tipos de datos (struct) deben estar documentadas siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- Cada tipo de dato implementado debe ser colocado en una unidad de compilación (archivo fuente) independiente.
Criterios de aprobación del Trabajo Práctico / Cursada de la materia
Para aprobar la cursada de la materia, se debe aprobar el Trabajo Práctico.
Estos son los criterios de aprobación:
- El software desarrollado funciona correctamente.
- El proyecto debe estar debidamente documentado siguiendo los estándares de documentación de cargo doc.
- Se debe hace uso de las herramientas cargo fmt para formatear el código fuente y de cargo clippy para asegurar que el código es lo más idiomático posible. No debe haber warnings de clippy.
- El trabajo del grupo fue desarrollado con un esfuerzo constante y parejo a lo largo del cuatrimestre.
- Se cumplieron los objetivos planteados y comprometidos con los tutores en las reuniones de seguimiento.
- Se desarrollaron tests unitarios y de integración de las partes importantes del proyecto.
- Se hizo un uso correcto de la metodología de trabajo con Github.
Examen Final 2do Cuatrimestre 2022
Enunciado para quienes cursaron en 2do cuatrimestre 2022
Se deberá implementar la extension al protocolo IRC denominada Direct Client-to-Client (DCC), para dar soporte a conversaciones seguras entre clientes y envio de archivos P2P.
Esta funcionalidad deberá poder acceder desde un botón u otro elemento en la interfaz gráfica del cliente desarrollado, en la ventana de chat con otro participante. Se deberá solicitar el archivo a enviar y se procederá a su envío.
Se deberá realizar una presentacion explicando la implementacion este agregado.
Requisitos funcionales
Se deberá considerar los siguientes requisitos:
- Mediante el uso de mensajes CTCP implementar las extensiones DCC CHAT y DCC SEND.
- El mensaje DCC CHAT es utilizado para iniciar una conversacion segura punto a punto entre dos clientes. La estructura del mismo es:
DCC CHAT <protocolo><ip><port>donde protocolo tiene el valorchat,ipes la direccion IP del cliente que inicia la conversacion yportes el puerto del cliente donde esperará por la conexion entrante. Para finalizar la comunicación se utiliza el mensajeDCC CLOSE - El mensaje DCC SEND es utilizado para iniciar la transferencia de un archivo entre clientes. La estructura del mensaje es:
DCC SEND <filename><ip><port><file size>dondefilenameyfile sizeson el nombre y tamano del archivo a enviar, IP es la direccion IP del cliente que inicia la transferencia del archivo yportes el puerto del cliente donde esperará por la conexión entrante. En caso de reanudar una transferencia interrumpida el cliente puede enviar la respuestaDCC RESUME <filename><port><position>para reanudar la transmision desde el punto indicado enposition.
Funcionalidad opcional
Extender el punto 3 para agregar soporte a algunas de las siguientes funcionalidades: encriptación, compresión y control de integridad. Para este punto pueden utilizar los siguientes crates externos:
Presentación
Se deberá realizar una presentacion explicando la implementacion este agregado, incluyendo las decisiones de diseño y una demostración de la funcionalidad.
El grupo deberá presentarse en una de las fechas de examen final, tal como se publica en el calendario respectivo.
Proyecto: Redis Oxidado - 1er Cuatrimestre 2021
Introducción
Redis es un almacenamiento principalmente en memoria, usado como una Base de Datos de tipo clave / valor en memoria, como también como caché y broker de mensajes, con opción a persistencia de los datos.
Redis soporta distintos tipos de estructuras de datos: strings, listas, hashmaps, sets, sets ordenados, bitmaps, entre varios otros.
Redis tiene una muy buena performance, dado que trabaja con los datos en memoria. Es posible persistir los datos periódicamente a un almacenamiento de disco.
Soporta otras funcionalidades como: transacciones, publishers/suscribers, clave con un tiempo de vida limitado, réplicas asincrónicas distribuidas, entre otras. Se puede utilizar clientes Redis desde la mayoría de los lenguajes de programación. Es un proyecto open source. Es una base de datos muy popular (la de mayor uso del tipo clave / valor).
Los usos principales de Redis son como cache de aplicación para mejorar los tiempos de latencia de una aplicación (y aumentar la capacidad de procesamiento de operaciones -requests- por segundo), para almacenar datos de sesión de los usuarios, o funcionalidades como limitar la cantidad de pedidos que puede realizar un cliente en cierto tiempo (rate limiter), para prevenir ataques de denegación de servicio, por ejemplo.
Otros casos de uso de Redis son la implementación del pasaje de mensajes entre publicadores y suscriptores de ciertos tipos de mensajes (que se suscriben a mensajes de algún tópico), o la implementación de colas de tareas para el procesamiento en paralelo de pedidos.
Objetivo del Proyecto
El objetivo del proyecto es implementar un Servidor Redis con funcionalidades acotadas, que se detallan en el presente enunciado.
Se presente emular, en la medida de lo posible, el proceso de desarrollo de la Industria de Software.
Criterios de Aceptación y Corrección del Proyecto
Para el desarrollo del proyecto, se deberá observar los siguientes lineamientos generales:
-
[Testing] Se deberá implementar testing unitario automatizado, utilizando las herramientas de Rust de los métodos y funciones relevantes implementados.
Se deberá implementar tests de integración automatizados, utilizando un cliente de Redis para el lenguaje Rust. Se podrá utilizar para ello, un crate externo que es la implementación de la biblioteca cliente de Redis. -
[Manejo de Errores] Deberá hacerse un buen uso y administración de los casos de error, utilizando para ello, las estructuras y herramientas del lenguaje, escribiendo en forma lo más idiomática posible el tratamiento.
-
[Control de versiones] Se deberá utilizar la herramienta git, siguiendo las recomendaciones de la cátedra. En particular, se deberá utilizar la metodología GitHub Flow para el trabajo con ramas (branches) y la entrega continua del software.
-
[Trabajo en equipo] Se deberá adecuar, organizar y coordinar el trabajo al equipo, realizando tareas como revisión de código cruzada entre pares de una funcionalidad en un pull request de git.
-
[Merge de Branchs] Para poder hacer el merge de un branch de una funcionalidad, todos los tests pasan de forma satisfactoria.
Evaluaciones
El desarrollo del proyecto tendrá un seguimiento directo semanal por parte del docente a cargo del grupo.
Se deberá desarrollar y presentar los avances y progreso del trabajo semana a semana (simulando un sprint de trabajo). Cada semana, cada docente realizará una valoración del estado del trabajo del grupo.
El progreso de cada semana deberá ser acorde a lo que se convenga con el docente para cada sprint. Si el mismo NO cumple con la cantidad de trabajo requerido, el grupo podrá estar desaprobado de forma prematura de la materia, a consideración del docente.
Se deja constancia que las funcionalidades requeridas por este enunciado son un marco de cumplimiento mínimo y que pueden haber agregados o modificaciones durante el transcurso del desarrollo por parte del docente a cargo, que formarán parte de los requerimientos a cumplir. Cabe mencionar que estos desvíos de los requerimientos iniciales se presentan en situaciones reales de trabajo con clientes.
Finalización del Proyecto
El desarrollo del proyecto finaliza el último día de clases del cuatrimestre. En esa fecha, cada grupo deberá realizar una presentación final y se hará una evaluación global del trabajo.
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución de los ejercicios:
- El proyecto deberá ser desarrollado en lenguaje Rust, usando las herramientas de la biblioteca estándar.
- No se permite utilizar crates externos. El único crate autorizado a ser utilizado es rand en caso de que se quiera generar valores aleatorios.
- El código fuente debe compilarse en la versión stable del compilador y no se permite utilizar bloques unsafe.
- El código deberá funcionar en ambiente Unix / Linux.
- El programa deberá ejecutarse en la línea de comandos.
- La compilación no debe arrojar warnings del compilador, ni del linter clippy.
- Las funciones y los tipos de datos (struct) deben estar documentadas siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- Las funciones no deben tener una extensión mayor a 30 líneas. Si se requiriera una extensión mayor, se deberá particionarla en varias funciones.
- Cada tipo de dato implementado debe ser colocado en una unidad de compilación (archivo fuente) independiente.
Requerimientos Funcionales
Las funcionalidades a implementar importantes requeridas
-
[1] Arquitectura: el programa a implementar sigue al modelo cliente-servidor, recibiendo solicitudes de servicio (requests) a través de la red (mediante sockets), y debe poder proveer servicio a mas de un cliente simultáneamente mediante el uso de threads.
-
[2] Configuración: el servidor deber poder ser configurado mediante un archivo de configuración, nombrado
redis.confy cuya ubicación se pasa por argumento de línea de comando:$ ./redis-server /path/to/redis.conf.
Las opciones de configuracion minimas son:verbose: un valor entero indicando si debe imprimir mensajes por consola, indicando el funcionamiento interno del servidor. Los mensajes a imprimir se dejan a criterio de la implementación.port: un valor entero indicando el puerto sobre el cual el servidor escucha para recibir requests.timeout: un valor entero indicando cuántos segundos esperar a que un cliente envíe un comando antes de cerrar la conexión. Si el valor es 0 se deshabilita el timeout.dbfilename: un string indicando el nombre del archivo en el cual se persistirán los datos almacenados. El valor por defecto esdump.rdb.logfile: un string indicando el nombre del archivo en el cual se grabara el log.
-
[3] Logs: el servidor debe mantener un registro de las acciones realizadas y los eventos ocurridos en un archivo de log.
La ubicación del archivo de log estará especificada en el archivo de configuración.
Como requerimiento particular del Proyecto, NO se considerará válido que el servidor mantenga un file handle global, aunque esté protegido por un lock, y que se escriba directamente al file handle. La arquitectura deberá contemplar otra solución.
-
[4] Protocolo Redis de request y response: El programa deberá implementar un subconjunto del protocolo Redis tal como es especificado en la documentación. Se sugiere tener funcionalidad para parsear los requests, para validar los requests, para implementar la lógica de cada comando, y que estas partes estén bien modularizadas.
En particular, no deben usarse expresiones regulares para desglosar los parámetros de los requests.
Los strings enviados y recibidos como parte del protocolo pueden ser strings UTF-8, y no necesariamente deben cumplir con el requerimiento de ser binary safe, i.e. no necesariamente son strings binarios arbitrarios, sino strings UTF-8 bien formados.
-
[5] Almacenamiento de datos: Los datos almacenados por el servidor deben estar en una estructura de datos global en memoria.
De manera automática, se debe almacenar periódicamente el contenido de los datos a un archivo cuya ubicación está especificada en el archivo de configuración mediante el parámetro
dbfilename. Al iniciarse el servidor, si este archivo existe, se deben cargar los datos desde el mismo. En otras palabras, si el servidor se detiene y reinicia, los datos deben volver a estar disponibles.Se deberá implementar la serialización y deserialización de la estructura de datos en memoria. Se reitera que para realizar esta tarea NO está permitido el uso de crates externos.
-
[6] Tipos de datos soportados: Los tipos de datos soportados por el servidor debe incluir strings, lists, y sets, pero NO
sorted setsohashes. -
[7] Vencimiento de claves (key expiration): el servidor debe proveer funcionalidad para setear un tiempo de expiración sobre una clave, de tal manera que transcurrido el tiempo indicado, la clave y su valor se eliminan automáticamente del conjunto de datos almacenados.
-
[8] Pub/sub: el servidor debe proveer funcionalidad para soportar el paradigma de mensajería pub/sub, en el cual clientes que envían mensajes (publicadores) no necesitan conocer la identidad de los clientes que reciben estos mensajes.
En cambio, los mensajes publicados se envían a un canal, y los clientes expresan interés en determinados mensajes subscribiéndose a uno o mas canales, y sólo reciben mensajes de estos canales, sin conocer la identidad de los publicadores. Para esto, el servidor debe mantener un registro de canales, publicadores y subscriptores. Para mas detalle, consultar la documentación de Redis.
Comandos que deben implementarse y soportarse
A continuación se lista los comandos que debe implementarse, separado.
Comandos del grupo server
- [9] info El comando INFO retorna información y estadísticas sobre el servidor en un formato fácil de parsear por computadores y fácil de leer por humanos.
- [10] monitor MONITOR es un comando de depuración que imprime al cliente cada comando procesado por el servidor. Puede ayudar entender qué está sucediendo en la base de datos.
- [11] flushdb Borra todas las claves de la base de datos. Este comando nunca falla.
- [12] config get El comando CONFIG GET se utiliza para leer los parámetros de configuración de un servidor en ejecución.
- [13] config set El comando CONFIG SET se utiliza para reconfigurar un servidor en tiempo de ejecución sin necesidad de reiniciarlo.
- [14] dbsize Retorna el numero de claves en la base de datos.
Comandos del grupo keys
-
[15] copy: Copia el valor almacenado en una clave origen a una clave destino.
-
[16] del: Elimina una clave específica. La clave es ignorada si no existe.
-
[17] exists: Retorna si la clave existe.
-
[18] expire: Configura un tiempo de expiración sobre una clave (la clave se dice que es volátil). Luego de ese tiempo de expiración, la clave es automáticamente eliminada.
-
[19] expireat: Tiene el mismo efecto que EXPIRE, pero en lugar de indicar el número de segundos que representa el TTL (time to live), toma el tiempo absoluto en el timestamp de Unix (segundos desde el 1ro de enero de 1970).
-
[20] keys: Retorna todas las claves que hacen match con un patrón.
-
[21] persist: Elimina el tiempo de expiración existente en una clave, tornando una clave volátil en persistente (una clave que no expira, dado que no tiene timeout asociado)
-
[22] rename: Renombra una clave a un nuevo nombre de clave.
-
[23] sort: Retorna los elementos contenidos en la lista o set, ordenados por la clave.
-
[24] touch: Actualiza el valor de último acceso a la clave.
-
[25] ttl: Retorna el tiempo que le queda a una clave para que se cumpla su timeout. Permite a un cliente Redis conocer cuántos segundos le quedan a una clave como parte del dataset.
-
[26] type: Retorna un string que representa el tipo de valor almacenado en una clave. Los tipos que puede retornar son: string, list, set (no consideramos los tipos de datos que no se implementan en el proyecto).
Comandos del grupo strings
-
[27] append Si la clave ya existe y es un string, este comando agrega el valor al final del string. Si no existe, es creada con el string vacío y luego le agrega el valor deseado. En este caso es similar al comando SET.
-
[28] decrby: Decrementa el número almacenado en una clave por el valor deseado. Si la clave no existe, se setea en 0 antes de realizar la operación.
-
[29] get: Devuelve el valor de una clave, si la clave no existe, se retorna el valor especial nil. Se retorna un error si el valor almacenado en esa clave no es un string, porque GET maneja solamente strings.
-
[30] getdel: obtiene el valor y elimina la clave. Es similar a GET, pero adicionalmente elimina la clave.
-
[31] getset: Atómicamente setea el valor a la clave deseada, y retorna el valor anterior almacenado en la clave.
-
[32] incrby: Incrementa el número almacenado en la clave en un incremento. Si la clave no existe, es seteado a 0 antes de realizar la operación. Devuelve error si la clave contiene un valor de tipo erróneo o un string que no puede ser representado como entero.
-
[33] mget: Retorna el valor de todas las claves especificadas. Para las claves que no contienen valor o el valor no es un string, se retorna el tipo especial nil.
-
[34] mset: Setea las claves data a sus respectivos valores, reemplazando los valores existentes con los nuevos valores como SET.
MSET es atómica, de modo que todas las claves son actualizadas a la vez. No es posible para los clientes ver que algunas claves del conjunto fueron modificadas, mientras otras no. -
[35] set: Setea que la clave especificada almacene el valor especificado de tipo string. Si la clave contiene un valor previo, la clave es sobreescrita, independientemente del tipo de dato contenido (descartando también el valor previo de TTL).
-
[36] strlen: Retorna el largo del valor de tipo string almacenado en una clave. Retorna error si la clave no almacena un string.
Comandos del grupo lists
-
[37] lindex: Retorna el elemento de la posición index en la lista almacenada en la clave indicada. El índice comienza en 0. Los valores negativos se pueden usar para determinar elementos desde el final de la lista: -1 es el último elemento, -2 es el anteúlitmo, y así.
Retorna error si el valor de esa clave no es una lista. -
[38] llen: Retorna el largo dela lista almacenada en la clave. Si la clave no existe, se interpreta como lista vacía, retornando 0. Se retorna error si el valor almacenado en la clave no es una lista.
-
[39] lpop Elimina y retorna el primer elemento de la lista almacenada en la clave. Se puede indicar un parámetro adicional count para indicar obtener esa cantidad de elementos.
-
[40] lpush: Inserta todos los valores especificados en el inicio de la lista de la clave especificada. Si no existe la clave, se crea inicialmente como una lista vacía para luego aplicar las operaciones. Se retorna error si la clave almacena un elemento que no es una lista.
-
[41] lpushx: Inserta los valores especificados al inicio de lalista, solamente si la clave existe y almacena una lista. A diferencia de LPUSH, no se realiza operación si la clave no existe.
-
[42] lrange: Retorna los elementos especificados de la lista almacenada en la clave indicada. Los inicios y fin de rango se consideran con el 0 como primer elemento de la lista. Estos valores pueden ser negativos, indicando que corresponde al final de la lista: -1 es el último elemento.
-
[43] lrem: Elimina la primer cantidad count de ocurrencias de elementos de la lista almacenada en la clave, igual al elemento indicado por parámetro. El parámetro cantidad influye de esta manera:
- count > 0: Elimina elementos iguales al indicado comenzando desde el inicio de la lista.
- count < 0: Elimina elementos iguales al indicado comenzando desde el final de la lista.
- count = 0: Elimina todos los elementos iguales al indicado.
-
[44] lset: Setea el elemento de la posición index de la lista con el elemento suministrado. Se retorna error si se indica un rango inválido.
-
[45] rpop: Elimina y obtiene el/los último/s elemento/s de la lista almacenada en la clave indicada. Por defecto, es un solo elemento, se puede indicar una cantidad.
-
[46] rpush: Inserta todos los valores especificados al final de la lista indicada en la clave. Si la clave no existe, se crear como una lista vacía antes de realizar la operación. Se retorna error si el elemento contenido no es una lista.
-
[47] rpushx: Inserta los valores especificados al final de la lista almacenada en la clave indicada, solamente si la clave contiene una lista. En caso contrario, no se realiza ninguna operación.
Comandos del grupo sets
-
[48] sadd: Agrega el elemento indicado al set de la clave especificada. Si la clave no existe, crea un set vacío para agregar el valor. Si el valor ya existía en el set, no se realiza agregado. Retorna error si el valor almacenado en la clave no es un set.
-
[49] scard: Retorna la cantidad de elementos del set almacenado en la clave indicada.
-
[50] sismember: Retorna si el elemento indicado es miembro del set indicado en la clave.
-
[51] smembers: Retorna todos los miembros del set almacenado en la clave indicada.
-
[52] srem: Elimina los miembros especificados del set almacenado en la clave indicada. Si la clave no existe, se considera como un set vacío, retornando 0. Retorna error si el valor almacenado en esa clave no es un set.
Comandos del grupo pubsub
-
[53] pubsub: Es un comando de análisis que permite inspeccionar el estado del sistema Pub/Sub.
La forma de este comando es:PUBSUB <subcommand> ... args ...Los subcomandos son:
-
CHANNELS: lista los canales activos. Un canal es lo que se conoce un canal Pub/Sub con uno o más suscriptores. Este comando admite un parámetro para especificar los patrones que deben cumplir los nombres de los canales, si no se especifica, se muestran todos.
Retorna una lista con los canales activos que cumplen con el patrón. -
NUMSUB: Devuelve el número de suscriptores de los canales especificados. El valor de retorno es la lista de canales y el número de suscriptores a cada uno. El formato es de una lista plana: canal, cantidad, canal, cantidad, ... El orden de la lista es el mismo que en los parámetros del comando.
-
NUMPAT: Este comando queda afuera del alcance del proyecto.
-
-
[54] publish: Envía (publica) un mensaje en un canal dado.
-
[55] subscribe: Suscribe al cliente al canal especificado.
-
[56] unsubcribe: Desuscribe al cliente de los canales indicados, si no se indica ninguno, lo desuscribe de todos.
Corriendo Redis y su cliente en Docker
- Instalar docker segun el sistema operativo que estes usando.
- Descargar y correr una imagen de docker con redis instalado:
docker run -d -p 6379:6379 --name redis-taller1 redis - Verificar que estar corriedo:
docker ps - Acceder a los logs de redis:
docker logs redis-taller1 - Ejecutar otro contenedor con la misma imagen, pero en modo interactivo y una shell:
docker exec -it redis-taller1 sh - Dentro de este contender, ejecutar el cliente:
redis-cli - Verificar que esta conectado al servidor redis:
127.0.0.1:6379> ping
PONG
- Ejecutar comandos redis:
127.0.0.1:6379> set name mark
OK
127.0.0.1:6379> get name
"mark"
127.0.0.1:6379> incr counter
(integer) 1
127.0.0.1:6379> incr counter
(integer) 2
127.0.0.1:6379> get counter
"2"
- Cerrar el cliente redis:
127.0.0.1:6379> exit
# exit
Agregado al proyecto: Monitor de Redis
Objetivo
Se debe implementar un sitio web para realizar operaciones sobre la base de datos Redis implementada en la primera parte del trabajo práctico.
Este servidor será similar a la demostración del sitio de Redis: https://try.redis.io/
Requerimientos Funcionales
Se debe implementar un servidor web que reciba pedidos (requests) de browsers, comunicándose con los mismos a través del protocolo HTTP/1.1. La descripción de este protocolo es la correspondiente a la RFC 2616.
El servidor debe escuchar pedidos HTTP en el puerto TCP 8080 y se comunicará con el servidor Redis desarrollado a partir del protocolo implementado.
Acerca de HTTP
El protocolo HTTP es usado globalmente para el intercambio de información en la Web desde 1990. Es orientado a cadenas de caracteres, HTTP es un protocolo de tipo cliente-servidor que opera con mensajes pedido/respuesta (request/reply). El cliente es el denominado agente de usuario (o user agent, en inglés) y puede ser un browser, un editor, un crawler u otro software para el usuario final. El servidor es un programa que acepta conexiones entrantes para responder a los pedidos (requests), con el envı́o de respuestas (replies).
HTTP provee encabezados (headers) para enviar el pedido, con métodos para indicar el tipo de pedido y define a la ubicación del recurso (por ejemplo, una "página web") referido a partir de su URI (Uniform Resource Identifier).
Funcionalidades a implementar
Al ingresar al sitio principal del sitio, se deberá mostrar una página web que deberá mostrar un recuadro donde el usuario podrá escribir comandos de Redis y debajo del mismo un botón "Enviar" que deberá invocar un comando HTTP POST. El servidor web deberá actuar como cliente Redis y conectarse al servidor implementado en la primera parte del Trabajo Práctico.
La respuesta del servidor Redis la deberá re-enviar el servidor web al browser y mostrar en un recuadro.
Se deberá implementar las comunicaciones HTTP entre el servidor web con mensajes del protocolo, respetando los headers.
Se deberá implementar el cliente del protocolo Redis hacia el servidor. NO se permite el uso de crates externos para la implementación del cliente Redis ni para el servidor HTTP.
Requerimientos no funcionales
- Valen los mismos requerimientos que para la primera parte del Trabajo Práctico.
Condiciones de aprobación
(Serán detalladas en clase)
Proyecto: MQTT Rústico - 2do Cuatrimestre 2021
Introducción
MQTT es un protocolo de mensajería basado en el patrón de comunicación publisher-suscriber y la arquitectura cliente-servidor. Dentro de sus principales características se puede destacar que es un protocolo liviano, simple y sencillo de implementar. Es un protocolo de capa de aplicación binario construido sobre TCP/IP, lo cual lo convierte en una forma de comunicarse sumamente eficiente con un overhead mínimo en la cantidad de paquetes que se envían a través de la red, a diferencia de otros protocolos de capa de aplicación, como por ejemplo HTTP.
Existen distintos estándares debido a que el protocolo ha ido evolucionando a través del tiempo (1.2, 3.1, 3.1.1, 5, etc). En particular, este proyecto estará centrado en la versión 3.1.1 del protocolo, cuya especificación puede encontrarse en el siguiente link: MQTT-v3.1.1
Su principal utilidad se da para implementar aplicaciones de IoT (Internet of Things), y se ha convertido en una forma estándar de comunicar dispositivos a través de la red. La principal causa de su éxito es que, gracias a sus características y funcionalidades ofrecidas, es un protocolo extremadamente simple, eficiente, sencillo de comprender e implementar y permite transferir datos a través de internet de forma confiable incluso por medio de canales de comunicación poco confiables.
Los requerimientos con los cuáles fue implementado el protocolo han sido son los siguientes:
- Que sea sencillo de implementar.
- Que se pueda especificar un nivel de calidad de servicio (Quality of Service, QoS) para la entrega de datos.
- Que sea liviano y eficiente en la red.
- Que sea agnóstico respecto de los datos que quieren comunicar las aplicaciones.
- Que permita a los clientes establecer sesiones para poder reconectarse en caso de sufrir una desconexión.
MQTT está basado en el patrón de comunicación publisher-subscriber. Esencialmente, es un patrón en el que existen clientes que quieren comunicar mensajes a través de tópicos, los cuáles son entregados a otros clientes que se encuentran suscritos a estos tópicos. Los clientes (publicadores y suscriptores) no se conocen entre sí, sino que envían los mensajes pertinentes con su respectivo tópico únicamente al servidor, cuya principal tarea es entregar los mensajes a los clientes que corresponda. Una buena ilustración que ejemplifica dicho patrón es la siguiente:

Como es posible observar, uno de los clientes envía un mensaje al servidor con el tópico temperatura, el cual llega al broker y es entregado a otros clientes que se encuentran suscritos a dicho tópico.
En la actualidad, existen distintas implementaciones de servidores MQTT, entre ellas:
- mosquitto, open-source y una de las más utilizadas.
- HiveMQ, que posee una versión abierta y otra paga.
- verneMQ.
A su vez, existen una serie de distintas implementaciones de clientes MQTT para distintos lenguajes.
Por último, se recomienda mirar los videos de la siguiente lista de reproducción, la cual explica a nivel general el funcionamientio del protocolo: MQTT Essentials
Objetivo del Proyecto
El objetivo del proyecto consiste en investigar el protocolo MQTT y realizar la implementación de una aplicación cliente y una aplicación servidor en el lenguaje de programación Rust. Además, la aplicación cliente deberá poseer una interfaz gráfica que permita interactuar con las distintas funcionalidades.
El objetivo secundario del proyecto consiste en el desarrollo de un proyecto real de software de mediana envergadura aplicando buenas prácticas de desarrollo de software, incluyendo entregas y revisiones usando un sistema de control de versiones.
Se espera que se haga un uso lo más idiomático posible del lenguaje de programación, siguiendo los estándares que éste promueve.
Evaluaciones
El desarrollo del proyecto tendrá un seguimiento directo semanal por parte del docente a cargo del grupo.
Se deberá desarrollar y presentar los avances y progreso del trabajo semana a semana (simulando un sprint de trabajo). Cada semana, o el o los docentes asignados a cada grupos realizarán una valoración del estado del trabajo del grupo.
El progreso de cada semana deberá ser acorde a lo que se convenga con el docente para cada sprint. Si el mismo NO cumple con la cantidad de trabajo requerido, el grupo podrá estar desaprobado de forma prematura de la materia, a consideración del docente.
Nota importante: Se deja constancia que las funcionalidades requeridas por este enunciado son un marco de cumplimiento mínimo y que pueden haber agregados o modificaciones durante el transcurso del desarrollo por parte del docente a cargo, que formarán parte de los requerimientos a cumplir. Cabe mencionar que estos desvíos de los requerimientos iniciales se presentan en situaciones reales de trabajo con clientes.
Finalización del Proyecto
El desarrollo del proyecto finaliza el último día de clases del cuatrimestre. En esa fecha, cada grupo deberá realizar una presentación final y se hará una evaluación global del trabajo.
Requerimientos no funcionales
Los siguientes son los requerimientos no funcionales para la resolución de los ejercicios:
- El proyecto deberá ser desarrollado en lenguaje Rust, usando las herramientas de la biblioteca estándar.
- No se permite utilizar crates externos. El único crate autorizado a ser utilizado es rand en caso de que se quiera generar valores aleatorios.
- El código fuente debe compilarse en la versión stable del compilador y no se permite utilizar bloques unsafe.
- El código deberá funcionar en ambiente Unix / Linux.
- El programa deberá ejecutarse en la línea de comandos.
- La compilación no debe arrojar warnings del compilador, ni del linter clippy.
- Las funciones y los tipos de datos (struct) deben estar documentadas siguiendo el estándar de cargo doc.
- El código debe formatearse utilizando cargo fmt.
- Las funciones no deben tener una extensión mayor a 30 líneas. Si se requiriera una extensión mayor, se deberá particionarla en varias funciones.
- Cada tipo de dato implementado debe ser colocado en una unidad de compilación (archivo fuente) independiente.
Requerimientos Funcionales
Protocolo
Configuración
El servidor MQTT tiene que poder ser inicializado con ciertos parámetros de configuración. Dichos parámetros deberán encontrarse especificados en un archivo de configuración con algún formato conveniente (no se puede utilizar ningún crate para parsear el archivo). Dentro de los parámetros de configuración, deben encontrarse:
- Puerto en cual el servidor escuchará por solicitudes (port).
- Path de archivo sobre el cuál se realizará un dump (ver más adelante).
- Intervalo de tiempo para el cual se realizará el dump (ver más adelante).
- Path de archivo de log (ver más adelante).
El path del archivo de configuración debe ser pasado como parámetro al ejecutable compilado del servidor.
Logging
Es necesario que el servidor loguee las distintas solicitudes que van llegando al mismo, así como también las distintas acciones que va realizando. El path del archivo donde se irán almacenando estos registros será especificado en el archivo de configuración.
El cumplimiento de este requerimiento puede ser implementado por dos vías:
- Implementando un log propio (No se considerará válido que el servidor mantenga un file handle global, aunque esté protegido por un lock, y que se escriba directamente al file handle. La arquitectura deberá contemplar otra solución.)
- Investigando y utilizando el crate tracing.
Autenticación
Una de las ventajas del protocolo MQTT es que ofrece la posibilidad de que los clientes deban autenticarse al conectarse al servidor. Para esto, dentro del mensaje de tipo CONNECT, deben especificar valores para los campos username y password. Para implementar esta funcionalidad, el servidor puede poseer un archivo de texto con los usuarios y sus contraseñas en texto plano.
Tipos de Paquetes
Se debe investigar e implementar los siguientes tipos de paquetes del protocolo:
- connect: Luego de establecida una conexión de red por el cliente hacia el servidor, el primer paquete enviado por el cliente es el CONNECT.
- connack: Paquete enviado por el servidor en respuesta a un paquete CONNECT recibido de un cliente.
- publish
- puback
- pubrel
- pubcomp
- subscribe
- suback
- unsubscribe
- unsuback
- pingreq
- pingresp
- disconnect
Quality of service (QoS)
- QoS 0 y 1 (de esta forma se encolan los mensajes de los clientes que están offline porque se desconectaron ungracefully y cuando se vuelven a conectar con el mismo clientId se le pueden enviar los mensajes).
Nota: no se implementará dentro del alcance del presente trabajo los mensajes de QoS 2.
Wilcards
- tiene que implementar las wildcards que se pueden utilizar para conformar un topic.
Sesiones persistentes
- tienen que implementar la persistent session (no hace falta que implementen el reenvío para los mensajes que no refieron el ACK, pero sí para los mensajes encolados).
Retained messages
- tienen implementar retained messages.
Last will & testament
- tienen que implementar last will & testament.
- se debe persistir la data necesaria para hacer el delivery de mensajes que no hayan podido ser entregados (respetando QoS nivel 1). Esto implica persistir id + mensajes no entregados.
Interfaz gráfica
La aplicación cliente deberá contar con una interfaz gráfica que permita interactuar con el servidor. Para realizar dicha aplicación, se debe utilizar el crate GTK. El grupo deberá investigar cómo utilizar dicho crate.
Requerimientos
La interfaz gráfica deberá contar con tres pestañas:
- Pestaña de conexión: Esta pestaña deberá contar con una serie de campos que permitan especificar los parámetros de conexión, y un botón para efectuar la misma. Los parámetros son:
- IP del servidor.
- Puerto del servidor al que hay que conectarse.
- clientId (el servidor debe poder discriminar entre clientes).
- Parámetros que deben ser incluidos en el paquete de tipo CONNECT:
- Nombre de usuario (username).
- Contraseña (password).
- lastWillMessage.
- lastWillTopic.
-
Pestaña de publicación: Esta pestaña permitirá enviar mensajes al servidor. En ella, se deberá poder ingresar un mensaje, un tópico, y tendrá que existir un botón para efectuar el envío. Una vez que el servidor confirme la recepción del mensaje, se deberá señalizar el éxito de la operación.
-
Pestaña de suscripción: Esta pestaña permitirá suscribirse a distintos tópicos y escuchar por los mensajes que sean publicados a estos. Para esto, se debe poder:
- Incluir un tópico del cual se desea escuchar por mensajes.
- Eliminar un tópico del cual no se desea seguir escuchando.
- Observar en tiempo real los mensajes que van llegando a los tópicos a los cuales se está suscrito, indicando cuál es tópico en cuestión.
Aclaración importante: El diseño de la interfaz y cómo se acomodan los componentes de la misma estará a cargo de cada grupo y será validada por los tutores asignados. Dicha interfaz debe cumplir con la cualidad de usabilidad, por lo que se recomienda hacer un diseño simple pero riguroso para cumplir con este requerimiento.
Finales Febrero/Marzo 2022
Para la aprobación final de la materia se deberá implementar un agregado al enunciado del Trabajo Práctico y exponerlo en alguna de las fechas de final del llamado febrero/marzo 2022.
Las presentaciones serán de forma remota a través de Internet. Los grupos deben inscribirse en el SIU Guaraní para la fecha de final.
Las fechas de examen son:
9508 // 7542 Taller de Programación I:
- miércoles 9/2 a las 18 hs
- miércoles 16/2 a las 18 hs
- miércoles 23/2 a las 18 hs
- miércoles 2/3 a las 18 hs
- miércoles 9/3 a las 18 hs
Enunciado
Se debe implementar el siguiente agregado al trabajo desarrollado:
Parte A) Implementar un programa que simule la generación de datos de un dispositivo (por ejemplo, la medición de la temperatura ambiente) cada determinado tiempo y lo publique como cliente al servidor MQTT utilizando un tópico predefinido. Este programa puede ser de consola, sin necesidad de interfaz gráfica, ni de interacción con el usuario.
Se permite utilizar el crate rand para la generación de valores.
Parte B) Implementar un programa cliente MQTT que se suscriba al tópico anterior para recibir los datos y que actúe como servidor HTTP para publicar y exponer esos datos a través de una web accesible desde el browser. Es decir, este programa debe actuar como servidor HTTP.
Investigar para ello, los lineamientos del protocolo de comunicación HTTP y del formato HTML. No es necesario que la página mostrada se actualice automáticamente.
Nota importante: No se permite el uso de crates externos de frameworks HTTP. Se debe implementar la comunicación y el servidor a partir del uso de sockets TCP, como se ha trabajado en el desarrollo del curso.
Grupo Rust Argentina
Invitamos a los alumnos de la materia y a toda la comunidad de la FIUBA a participar del grupo Rust Argentina.
Nosotros
Conozca a los integrantes del equipo de la cátedra de Taller de Programación en Rust.

